In the dynamic field of digital content creation using generative models, state-of-the-art video editing models still do not offer the level of quality and control that users desire. Previous works on video editing either extended from image-based generative models in a zero-shot manner or necessitated extensive fine-tuning, which can hinder the production of fluid video edits. Furthermore, these methods frequently rely on textual input as the editing guidance, leading to ambiguities and limiting the types of edits they can perform. Recognizing these challenges, we introduce AnyV2V, a novel tuning-free paradigm designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model to modify the first frame, (2) utilizing an existing image-to-video generation model to generate the edited video through temporal feature injection. AnyV2V can leverage any existing image editing tools to support an extensive array of video editing tasks, including prompt-based editing, reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. AnyV2V can also support any video length. Our evaluation indicates that AnyV2V significantly outperforms other baseline methods in automatic and human evaluations by significant margin, maintaining visual consistency with the source video while achieving high-quality edits across all the editing tasks.
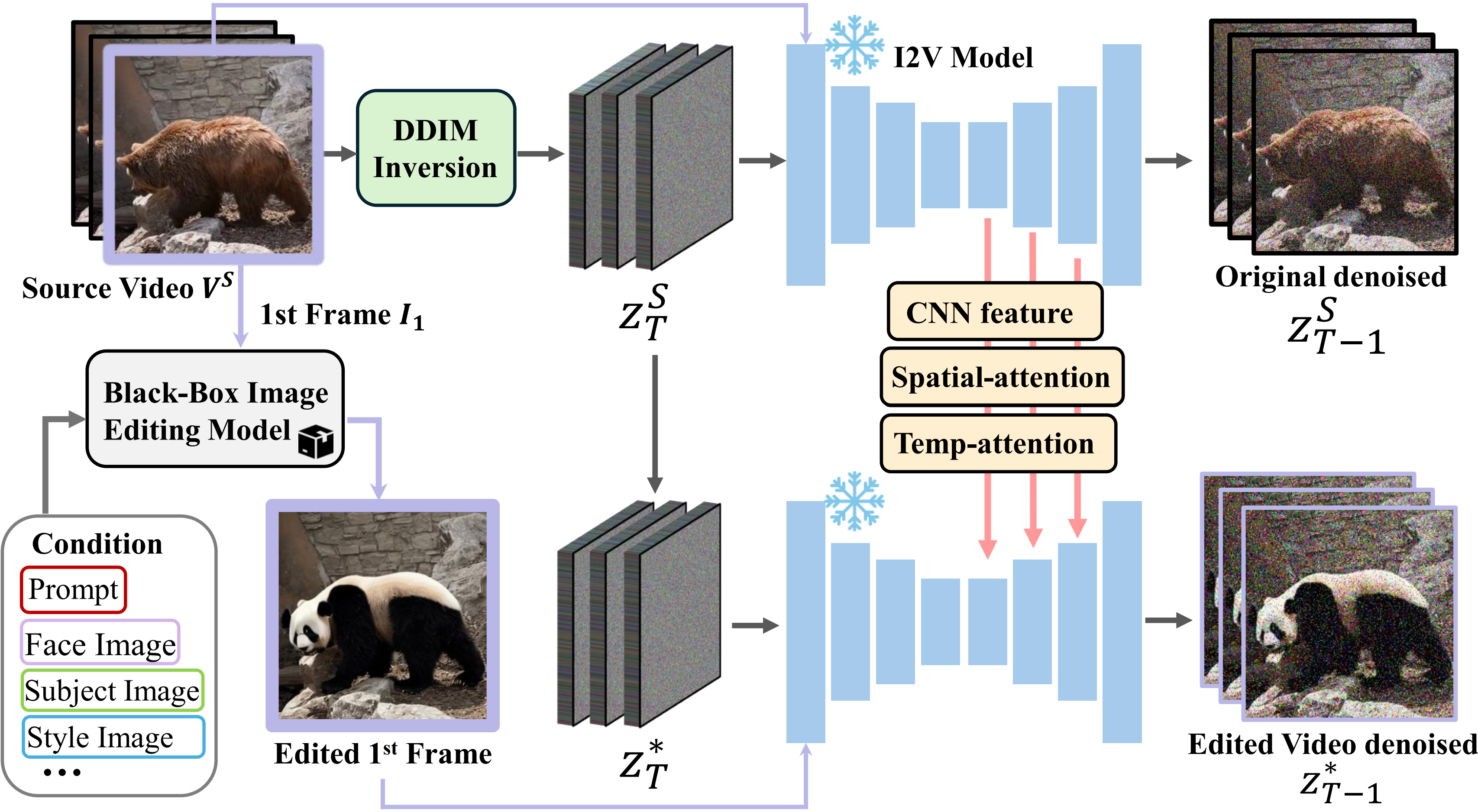
AnyV2V disentangles the video editing process into two stages: (1) first-frame image editing and (2) image-to-video reconstruction. The first phase benefits from the extensive range of existing image editing models, enabling (1) detailed and precise modification and (2) flexibility for any editing tasks.
AnyV2V framework takes a source video as input. In the first stage, we apply a block-box image editing method on the first frame according to the editing task. In the second stage, the source video is inverted to initial noise, which is then denoised using DDIM sampling. During the sampling process, we extract spatial features, spatial attention and temporal attention from the image-to-video' decoder layers. To generate our edited video, we perform a DDIM sampling by fixing the latent and use the edited first frame as the conditional signal. During the sampling, we inject the features and attention into corresponding layers of the model.
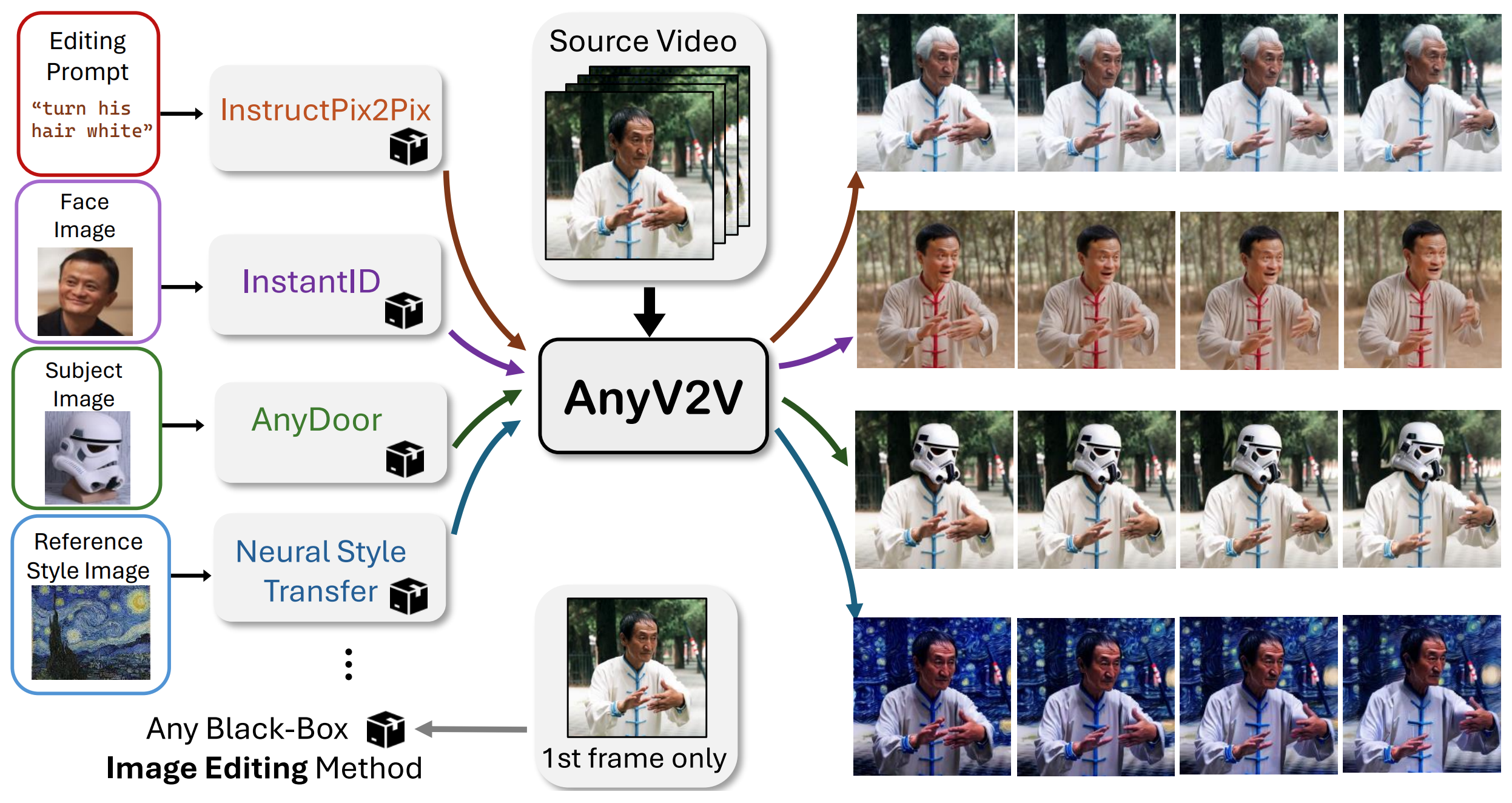
AnyV2V is robust in a wide range of localized editing tasks while maintaining the background. The generated result aligns the most with the text prompt and also maintains high motion consistency.
Given one subject image, AnyDoor-equipped AnyV2V replaces an object in the video with the target subject while maintaining the video motion and persevering the background.




AnyV2V uses NST / InstantStyle for the 1st frame style edits. Prior text-based methods struggle with unseen styles. In contrast, AnyV2V seamlessly transfers any reference style to the video, uniquely allowing artists to use their own creations as references.




Integrating the InstantID, AnyV2V enables swapping a person's identity in a video with a single-reference face image. To the best of our knowledge, our work is the first to provide such flexibility in the video editing domain.


AnyV2V can perform video editing beyond the training frames of the I2V Model.
AnyV2V can preserve the video fidelity while performing the correct amount of edit.
Source |
AnyV2V(Ours) |
TokenFlow |
FLATTEN |
Source |
Reference |
AnyV2V(Ours) |
VideoSwap |

|
|||

|
@article{ku2024anyv2v,
title={AnyV2V: A Tuning-Free Framework For Any Video-to-Video Editing Tasks},
author={Ku, Max and Wei, Cong and Ren, Weiming and Yang, Harry and Chen, Wenhu},
journal={arXiv preprint arXiv:2403.14468},
year={2024}
}