Video Gallery
Input Frame
Output Video
Input Frame
Output Video
Input Frame
Output Video















Input Frame
Output Video
Input Frame
Output Video
Input Frame
Output Video
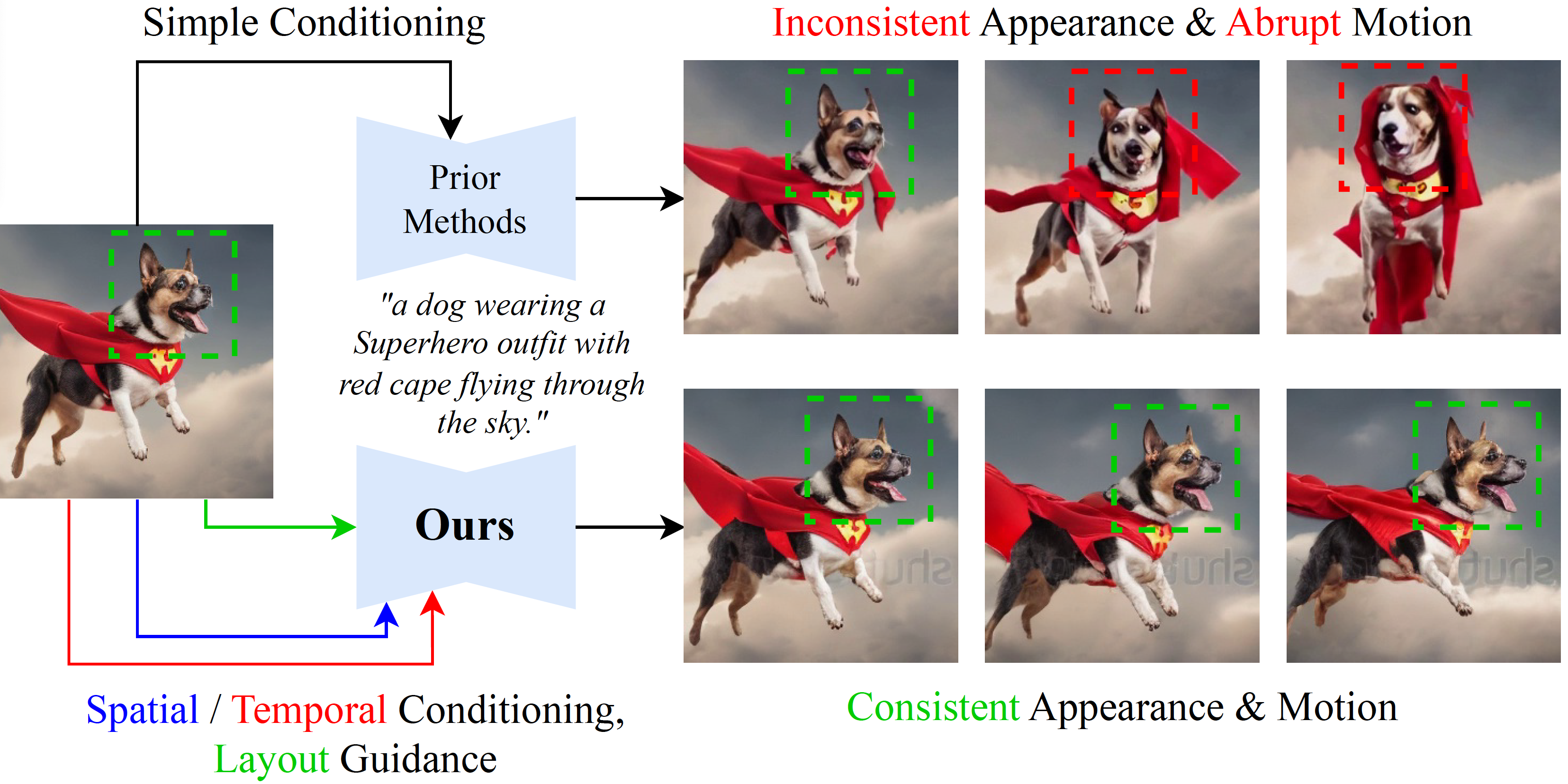
Image-to-video (I2V) generation aims to use the initial frame (alongside a text prompt) to create a video sequence. A grand challenge in I2V generation is to maintain visual consistency throughout the video: existing methods often struggle to preserve the integrity of the subject, background, and style from the first frame, as well as ensure a fluid and logical progression within the video narrative. To mitigate these issues, we propose ConsistI2V, a diffusion-based method to enhance visual consistency for I2V generation. Specifically, we introduce (1) spatiotemporal attention over the first frame to maintain spatial and motion consistency, (2) noise initialization from the low-frequency band of the first frame to enhance layout consistency. These two approaches enable ConsistI2V to generate highly consistent videos. We also extend the proposed approaches to show their potential to improve consistency in auto-regressive long video generation and camera motion control. To verify the effectiveness of our method, we propose I2V-Bench, a comprehensive evaluation benchmark for I2V generation. Our automatic and human evaluation results demonstrate the superiority of ConsistI2V over existing methods.
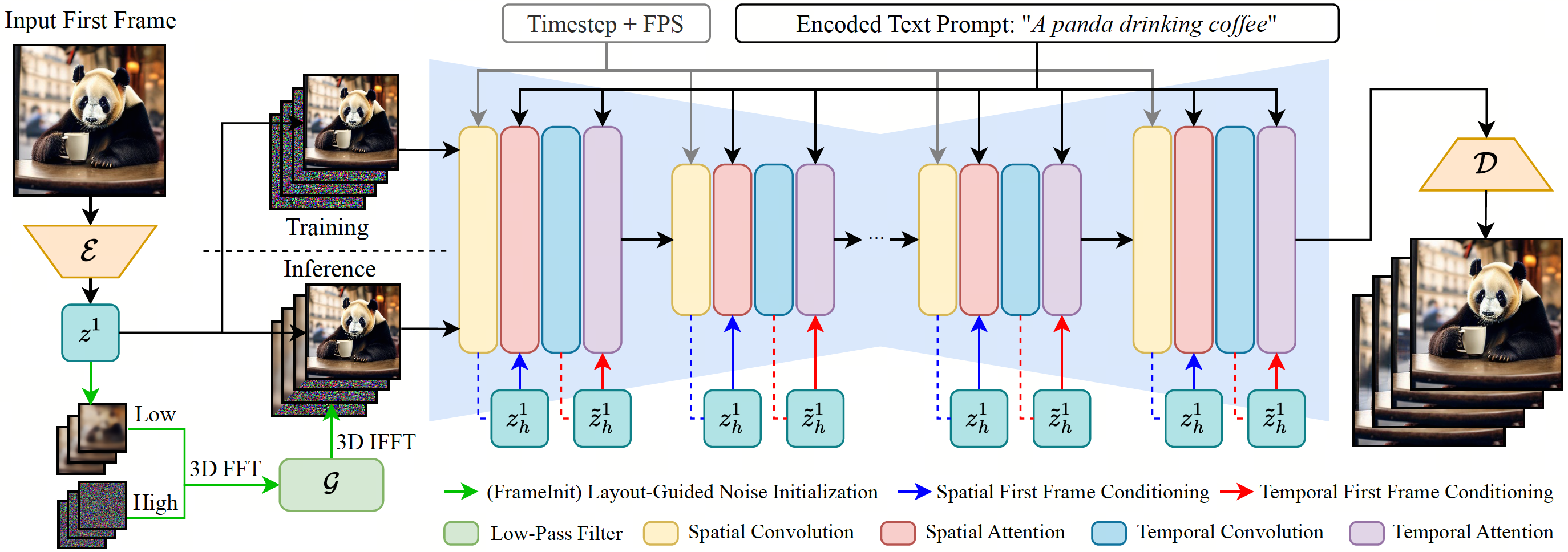
In our model, we concatenate the first frame latent to the input noise and perform first frame conditioning by augmenting the spatial and temporal self-attention operations in the model with the intermediate hidden states. During inference, we propose FrameInit, which incorporate the low-frequency component from the first frame latent to initialize the inference noise and guide the video generation process.
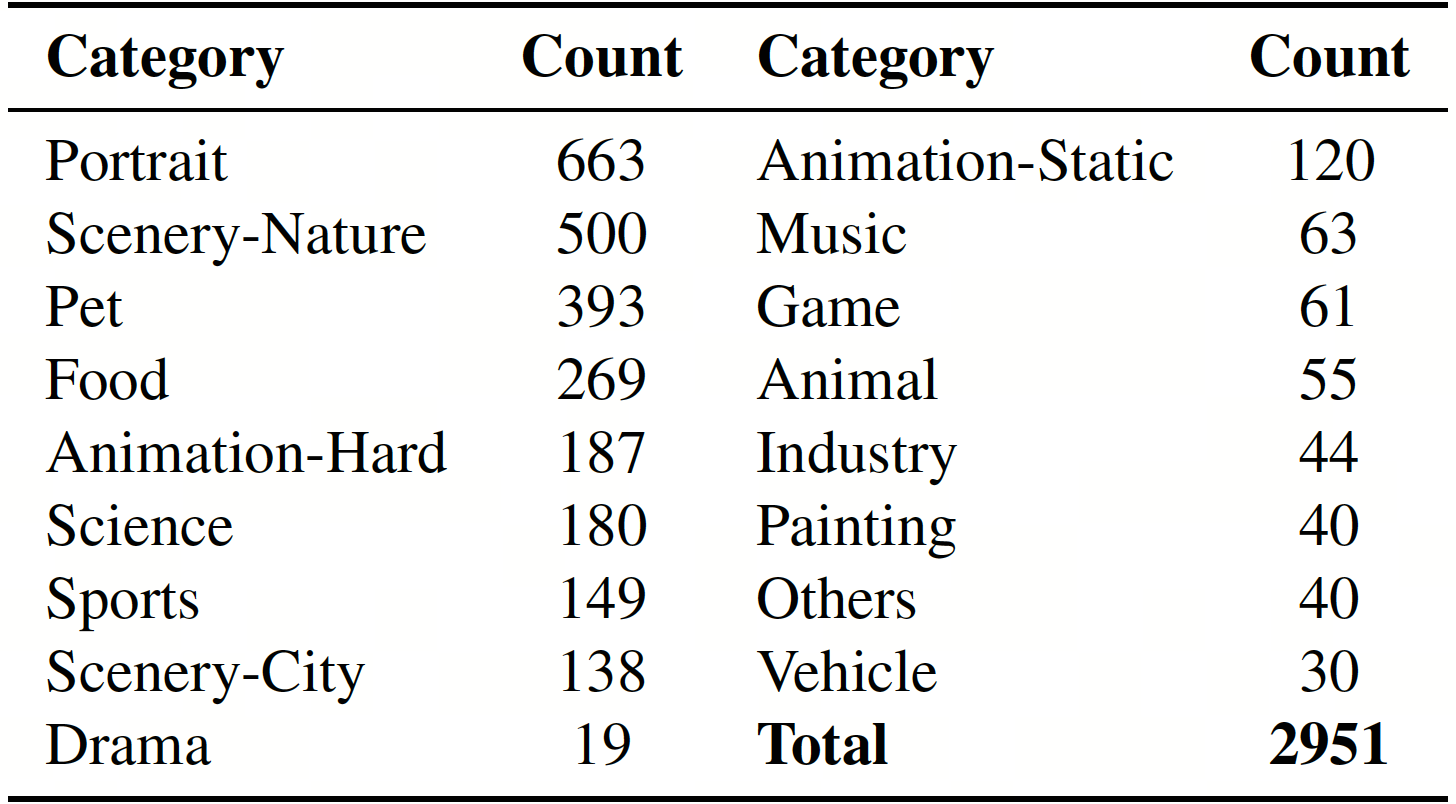
Existing video generation benchmarks such as UCF-101 and MSR-VTT fall short in video resolution, diversity, and aesthetic appeal. To bridge this gap, we introduce the I2V-Bench evaluation dataset, featuring 2,951 high-quality YouTube videos curated based on strict resolution and aesthetic standards. We organized these videos into 16 distinct categories, such as Scenery, Sports, Animals, and Portraits. Our evaluation framework encompasses two key dimensions, each addressing distinct aspects of Image-to-Video (I2V) performance: (1) Visual Quality assesses the perceptual quality of the video output regardless of the input prompts. We measure the subject and background consistency, temporal flickering, motion smoothness and dynamic degree. (2) Visual Consistency evaluates the video's adherence to the text prompt given by the user. We measure object consistency, scene consistency and overall video-text consistency.
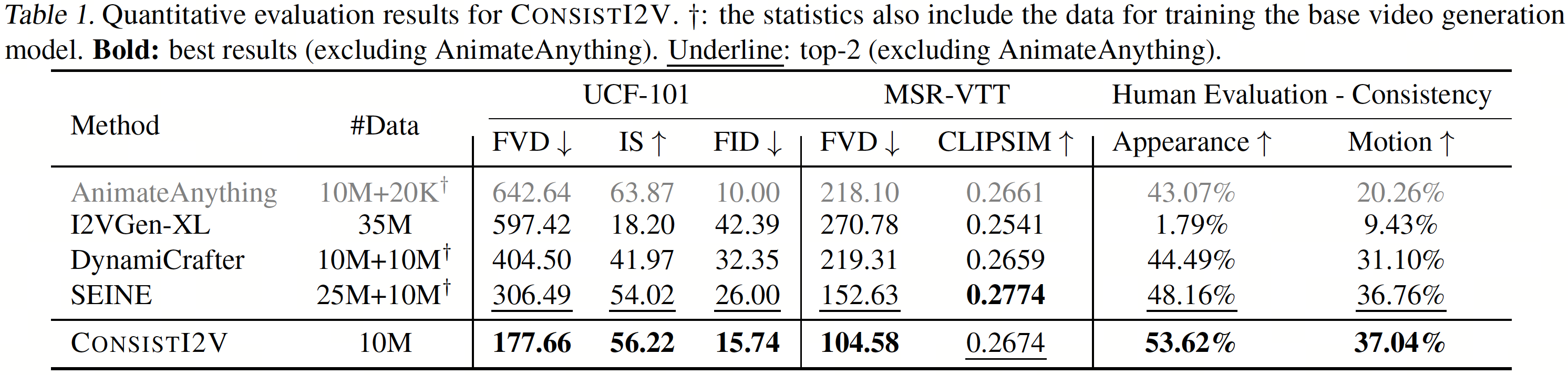
We perform extensive automatic evaluations on UCF-101 and MSR-VTT and human evaluations on 548 generated samples from our ConsistI2V and the baseline models. Our model significantly outperforms the baseline models in all metrics, except for CLIPSIM on MSR-VTT, where the result is slightly lower than SEINE. We also conduct automatic evaluations on I2V-Bench and observe that our model achieves a better balance between motion magnitude and video quality, outperforms all other baseline models excluding AnimateAnything in terms of motion quality (less flickering and better smoothness) and visual consistency (higher background/subject consistency) and achieves a competitive overall video-text consistency.
While our I2V generation model provides native support for long video generation by reusing the last frame of the previous video to generate the subsequent video, we observe that directly using the model to generate long videos may lead to suboptimal results, as the artifacts in the previous video clip will often accumulate throughout the autoregressive generation process. We find that using FrameInit to guide the generation of each video chunk helps stabilize the autoregressive video generation process and results in a more consistent visual appearance throughout the video.

When adopting FrameInit for inference, instead of using the static first frame video as the input, we can alternatively create synthetic camera motions from the first frame and use it as the layout condition. For instance, camera panning can be simulated by creating spatial crops in the first frame starting from one side and gradually moving to the other side. By simply tweaking the FrameInit parameters and using the synthetic camera motion as the layout guidance, we are able to achieve camera panning and zoom-in/zoom-out effects in the generated videos.

@article{ren2024consisti2v,
title={ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation},
author={Ren, Weiming and Yang, Harry and Zhang, Ge and Wei, Cong and Du, Xinrun and Huang, Stephen and Chen, Wenhu},
journal={arXiv preprint arXiv:2402.04324},
year={2024}
}