
We introduce 🦣MAmmoTH, a series of open-source large language models (LLMs) specifically tailored for general math problem-solving. The MAmmoTH models are trained on MathInstruct, our meticulously curated instruction tuning dataset. MathInstruct is compiled from 13 math datasets with intermediate rationales, six of which have rationales newly curated by us. It boasts the hybrid of chain-of- thought (CoT) and program-of-thought (PoT) rationales, and also ensures exten- sive coverage of diverse fields in math. The hybrid of CoT and PoT can not only unleash the potential of tool use but also allow different thought processes for dif- ferent math problems. As a result, the MAmmoTH series substantially outperform existing open-source models on nine mathematical reasoning datasets across all scales with an average accuracy gain ranging from 12% to 29%. Remarkably, our MAmmoTH-7B model reaches 35% on MATH (a competition-level dataset), which exceeds the best open-source 7B model (WizardMath) by 25%, and the MAmmoTH-34B model achieves 46% accuracy on MATH, even surpassing GPT- 4’s CoT result. Our work underscores the importance of diverse problem coverage and the use of hybrid rationales in developing superior math generalist models.
| Training Dataset | Type | Annotation | Samples | Characteristics | Fields |
|---|---|---|---|---|---|
| GSM8K | CoT | Human | 7K | Grade Schol Exam | Pre-Algebra |
| GSM8K-RFT | CoT | Llama | 28K | Llama + Validated | Pre-Algebra |
| AQuA-RAT | CoT | Human | 90K | GRE/GMAT Exam | Inter-Algebra |
| MATH | CoT | Human | 7K | Math Competition | Pre-Algebra, Inter-Algebra, Algebra, Probability, NumTheory, Calculus, Geometry |
| TheoremQA | CoT | GPT-4 | 600 | GPT4 + Validated | Algebra, Probability, NumTheory, Calculus, Geometry |
| Camel-Math | CoT | GPT-4 | 50K | GPT4 (Unvalidated) | Algebra, Probability, NumTheory, Calculus, Geometry |
| College-Math | CoT | GPT-4 | 1.8K | GPT4 (Unvalidated) | Algebra |
| GSM8K | PoT | GPT4 | 14K | GPT4 + Validated | Pre-Algebra |
| AQuA-RAT | PoT | GPT4 | 9.7K | GPT4 + Validated | Inter-Algebra |
| MATH | PoT | GPT4 | 7K | GPT4 + Validated | Pre-Algebra, Inter-Algebra, Algebra, Probability |
| TheoremQA | PoT | GPT4 | 700 | GPT4 + Validated | Algebra, Probability, NumTheory, Calculus, Geometry |
| MathQA | PoT | Human | 25K | AQuA-RAT Subset | Inter-Algebra |
| NumG | PoT | Human | 13K | Lila Annotated | Pre-Algebra |
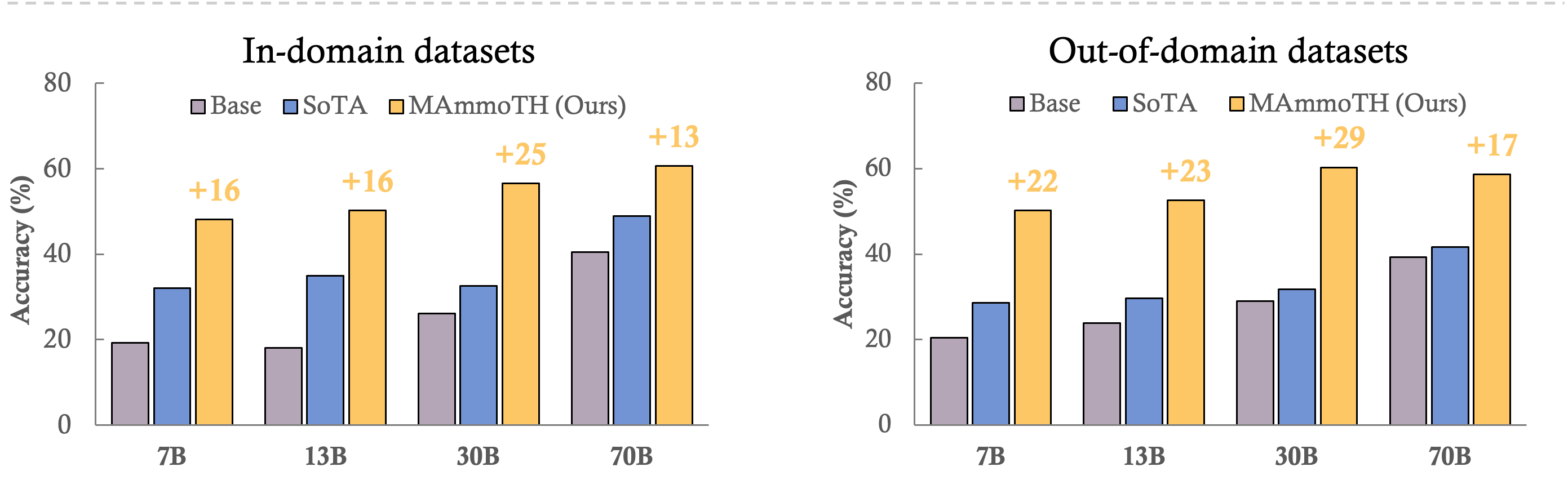
Overall, we can see that MAmmoTH and MAmmoTH-Coder are able to outperform the SoTA model at different scales. In general, the performance gain for OOD datasets is more significant than IND datasets. These results show us the potential of our models as a mathematical generalist. On several datasets, MAmmoTH-Coder-34B and MAmmoTH-70B are even surpassing closed-source LLMs (see more break down results below).
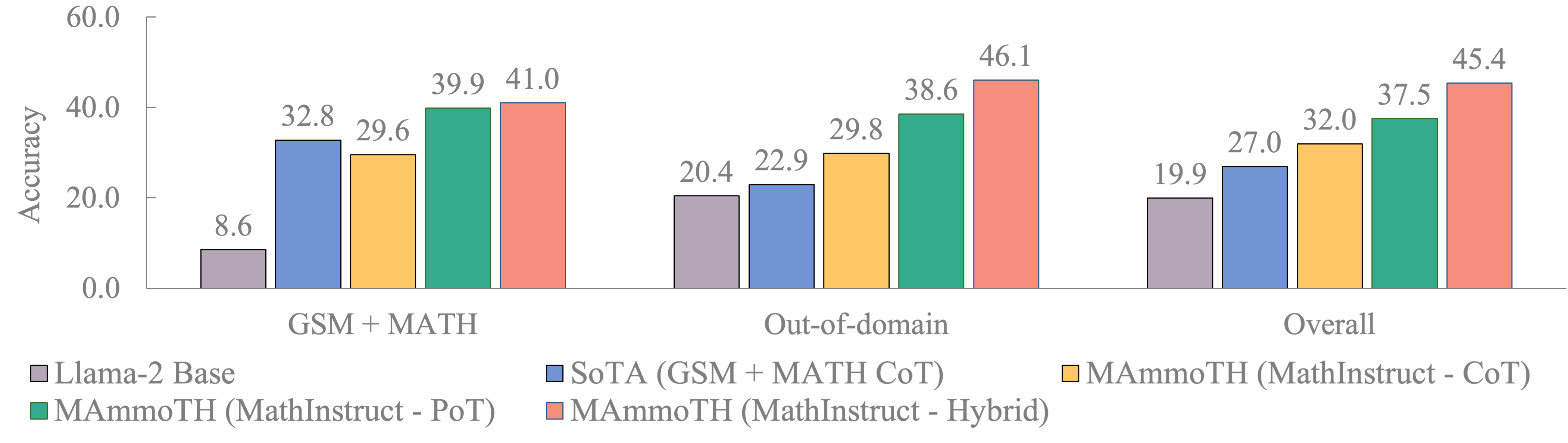
In order to better understand what factors contribute to the great gain of 🦣MAmmoTH over existing baselines, we set up a group of control experiments in the Figure 3. We study the following setups:
| Model | GSM8K | MATH | AQuA | NumG | SVAMP | Mathematics | SimulEq | SAT | MMLU | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Closed-source Model | |||||||||||||
| GPT-4 | - | Unknown | 92 | 42.5 | 72.6 | - | - | 97 | - | - | 95 | - | - |
| Code-Interpreter | - | Unknown | 97 | 69.7 | - | - | - | - | - | - | - | - | - |
| PaLM-2 | - | Unknown | 80.7 | 34.3 | 64.1 | - | - | - | - | - | - | - | - |
| Claude-2 | - | Unknown | 85.2 | 32.5 | 60.9 | - | - | - | - | - | - | - | - |
| Codex (PoT) | - | No | 71.6 | 36.8 | 54.1 | - | - | 85.2 | - | - | 68 | - | - |
| 7B Parameter Model | |||||||||||||
| Llama-1 | - | No | 10.7 | 2.9 | 22.6 | 24.7 | 15.5 | 24.5 | 6.2 | 4.6 | 22.7 | 30.6 | 17.7 |
| Llama-2 | - | No | 14.6 | 2.5 | 30.3 | 29.9 | 19.3 | 34.5 | 6 | 5 | 26.8 | 29.8 | 20.4 |
| Galactica-6.7B | GAL | GAL-Instruct | 10.2 | 2.2 | 25.6 | 25.8 | 15.9 | 25.6 | 4.6 | 4.2 | 17.5 | 28 | 16 |
| Code-Llama (PoT) | - | No | 25.2 | 14.2 | 24 | 26.8 | 22.3 | 49.4 | 21.7 | 3.5 | 28.6 | 26.9 | 26 |
| AQuA-SFT | Llama-2 | AQuA | 11.2 | 3.6 | 35.6 | 12.2 | 15.6 | - | - | - | - | - | - |
| Llama-1 RFT | Llama-1 | GSM8K | 46.5 | 5.2 | 18.8 | 21.1 | 22.9 | 21.1 | 5.1 | 11 | 12.5 | 21.7 | 14.3 |
| WizardMath | Llama-2 | GSM8K+MATH | 54.9 | 10.7 | 26.3 | 36.1 | 32 | 36.1 | 9.3 | 12.8 | 25.4 | 31.1 | 28.6 |
| MAmmoTH | Llama-2 | MathInstruct | 53.6 | 31.5 | 44.5 | 61.2 | 61.2 | 67.7 | 46.3 | 41.2 | 42.7 | 42.6 | 48.1 |
| MAmmoTHc | Code-Llama | MathInstruct | 59.4 | 33.4 | 47.2 | 66.4 | 51.6 | 71.4 | 55.4 | 45.9 | 40.5 | 48.3 | 52.3 |
| $\Delta$ | +5 | +21 | +12 | +30 | +20 | +22 | +34 | +33 | +14 | +17 | +24 | ||
| 13-15B Parameter Model | |||||||||||||
| Llama-1 | - | No | 17.8 | 3.9 | 26 | 24.8 | 18.1 | 34.7 | 6.9 | 5.4 | 27.7 | 30.7 | 21 |
| Llama-2 | - | No | 28.7 | 3.9 | 25.1 | 8.8 | 16.6 | 35.1 | 11.5 | 5.8 | 32.7 | 34.4 | 23.9 |
| Code-Llama (PoT) | - | No | 36.1 | 18.1 | 28.7 | 29.2 | 28 | 60 | 21.3 | 3.8 | 25.9 | 27.7 | 27.7 |
| CodeT5+ (PoT) | - | No | 12.5 | 2.4 | 20.5 | 19.4 | 13.7 | - | - | - | - | - | - |
| CodeGen+ (PoT) | - | No | 12.7 | 3.4 | 24.5 | 22.5 | 15.7 | - | - | - | - | - | - |
| Vicuna-1.5 | Llama-2 | No | 28.4 | 5.8 | 24.8 | 36.9 | 23.9 | 55.7 | 10 | 6.6 | 34 | 34.1 | 28.1 |
| Llama-1 RFT | Llama-1 | GSM8K | 52.1 | 5.1 | 16.1 | 24.5 | 24.4 | 46.5 | 6.7 | 10.1 | 13.2 | 21.6 | 19.6 |
| Orca-Platypus | Llama-2 | Platypus | 38.4 | 3 | 18.9 | 35.3 | 23.9 | 56.8 | 12.6 | 7.9 | 29.5 | 41.6 | 29.7 |
| Platypus | Llama-2 | Platypus | 25.7 | 2.5 | 33.4 | 42.3 | 25.9 | 55.4 | 11.4 | 7.4 | 36.8 | 35.5 | 29.3 |
| WizardMath | Llama-2 | GSM8K+MATH | 63.9 | 14 | 21.2 | 40.8 | 34.9 | 51.9 | 14.1 | 14.9 | 24.5 | 32.1 | 27.5 |
| MAmmoTH | Llama-2 | MathInstruct | 62.0 | 34.2 | 51.6 | 68.7 | 54.1 | 72.4 | 49.2 | 43.2 | 46.8 | 47.6 | 51.8 |
| MAmmoTHc | Code-Llama | MathInstruct | 64.7 | 36.3 | 46.9 | 66.8 | 53.7 | 73.7 | 61.5 | 47.1 | 48.6 | 48.3 | 55.8 |
| $\Delta$ | +1 | +20 | +18 | +26 | +19 | +14 | +40 | +33 | +12 | +7 | +26 | ||
| 30-34B Parameter Model | |||||||||||||
| Llama-1 | - | No | 35.6 | 7.1 | 33.4 | 28.4 | 26.1 | 48.8 | 12.8 | 11.2 | 33.4 | 39 | 29 |
| Code-Llama (PoT) | - | No | 44 | 25 | 25.2 | 29.3 | 30.8 | 69.1 | 34.5 | 6.8 | 26.8 | 21.6 | 31.7 |
| Llama-1 RFT | Llama-1 | GSM8K | 56.5 | 7.4 | 18.5 | 24.3 | 26.6 | 55.4 | 7.6 | 12.8 | 20.4 | 37.9 | 26.8 |
| Galactica-30B | GAL | GAL-Instruct | 41.7 | 12.7 | 28.7 | 34.7 | 29.4 | 41.6 | 11.8 | 13.2 | 37.7 | 37.9 | 28.4 |
| Platypus | Llama-1 | Platypus | 37.8 | 10.1 | 27.9 | 40.5 | 29.1 | 51.7 | 13.8 | 13.6 | 38.6 | 41 | 31.7 |
| Tulu | Llama-2 | Tulu | 51 | 10.8 | 25.5 | 43.4 | 32.6 | 59 | 10.7 | 10.3 | 31.3 | 39.8 | 30.2 |
| MAmmoTHc | Code-Llama | MathInstruct | 72.7 | 43.6 | 54.7 | 71.6 | 60.7 | 84.3 | 65.4 | 51.8 | 60.9 | 53.8 | 63.2 |
| $\Delta$ | +16 | +21 | +21 | +28 | +28 | +15 | +31 | +38 | +22 | +13 | +32 | ||
| 65-70B Parameter Model | |||||||||||||
| Llama-1 | - | No | 50.9 | 10.6 | 35 | 50.2 | 36.6 | 55.3 | 14.2 | 15.2 | 37.4 | 44.1 | 33.2 |
| Llama-2 | - | No | 56.8 | 13.5 | 40.9 | 50.4 | 40.4 | 63.8 | 20.5 | 14 | 51.3 | 47.1 | 39.3 |
| Llama-2-Chat | Llama-2 | No | 54.9 | 18.6 | 37 | 51.6 | 40.5 | 71.5 | 19.2 | 21.7 | 44.1 | 46.9 | 40.6 |
| Guanaco | Llama-2 | No | 59.2 | 4.1 | 45.2 | 53.5 | 40.5 | 66.8 | 17.8 | 20.2 | 50 | 47.3 | 40.4 |
| WizardMath | Llama-2 | GSM8K+MATH | 81.6 | 22.7 | 20 | 48.9 | 43.3 | 71.8 | 17.1 | 37.9 | 13.2 | 27.4 | 33.4 |
| Platypus | Llama-2 | Platypus | 70.6 | 18.6 | 51.2 | 55.4 | 48.9 | 51.8 | 26.3 | 21.7 | 55.9 | 52.5 | 41.6 |
| MAmmoTH | Llama-2 | MathInstruct | 76.9 | 41.8 | 65.0 | 74.4 | 64.5 | 82.4 | 55.6 | 51.4 | 66.4 | 56.7 | 62.5 |
| $\Delta$ | -5 | +19 | +14 | +19 | +16 | +11 | +29 | +14 | +11 | +4 | +21 | ||
@article{yue2023mammoth,
title={MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning},
author={Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen},
journal={arXiv preprint arXiv:2309.05653},
year={2023}
}