Mantis: Interleaved Multi-Image Instruction Tuning
Balancing Multi-Image and Single-Image Abilities of Large Multimodal Models
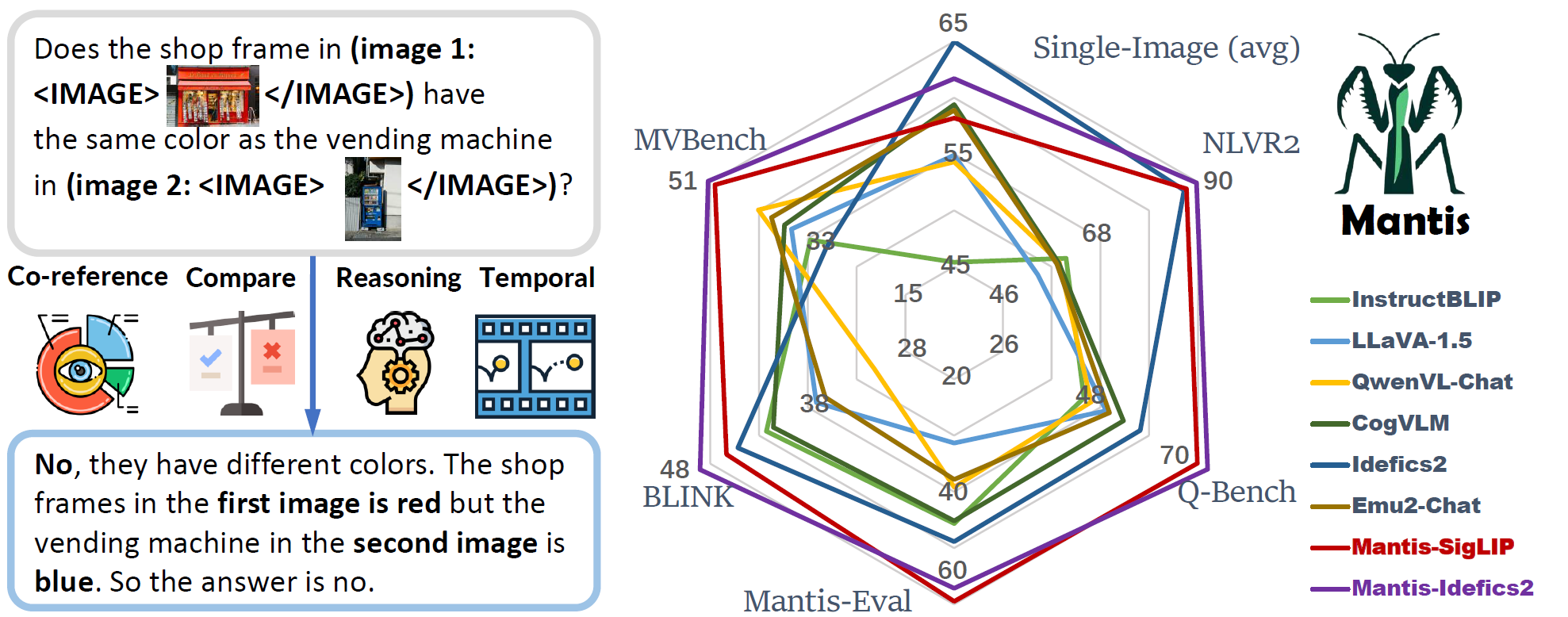
🤔 The recent years have witnessed a great array of large multimodal models (LMMs) to effectively solve single-image vision language tasks. However, their abilities to solve multi-image visual language tasks is yet to be improved.
😦 The existing multi-image LMMs (e.g. OpenFlamingo, Emu, Idefics, etc) mostly gain their multi-image ability through pre-training on hundreds of millions of noisy interleaved image-text data from web, which is neither efficient nor effective.

| Subset | Multi-Image Skill | Sample Size |
|---|---|---|
| LLaVA-665k-multi | Coref | 313K |
| LRV-multi | Coref | 8K |
| NLVR2 | Reason | 86K |
| IconQA | Reason | 64K |
| Contrast-Caption | Reason | 36K |
| ImageCoDe | Reason | 17K |
| Multi-VQA | Reason | 5K |
| Co-Instruct | Compare | 151K |
| Dreamsim | Compare | 16K |
| Spot-the-Diff | Compare | 8K |
| Birds-to-Words | Compare | 3K |
| VIST | Temporal | 7K |
| NExT-QA | Temporal | 4K |
| STAR | Temporal | 3K |
Mantis applies the LLaVA's architecture, using CLIP/SigLIP as vision encoders and Meta-Llama-3-8B-Instruct as language model. We consider a two-stage instruction-tuning procedure: connects pre-trained CLIP ViT-L/14 visual encoder and large language model Vicuna, using a simple projection matrix. To support super-resolution, we also train a variant based on SigLIP and Fuyu-8B. We also train a variant Mantis-8B-Idefics2 based on idefics2-8b, which is the most competitive model of Mantis family. Please check out our [Model Zoo].
| Benchmark | Multi-Image Skill | Held-in/Held-out |
|---|---|---|
| NLVR2 | Reason | Held-in |
| Q-bench | Reason | Held-in |
| Mantis-Eval | Reason & Co-reference | Held-out |
| BLINK | Reason | Held-out |
| MVBench | Temporal | Held-out |
We select 5 multi-image benchmarks that cover the four crucial multi-image skills: co-reference, reasoning, comparing, temporal understanding to evaluate Mantis.
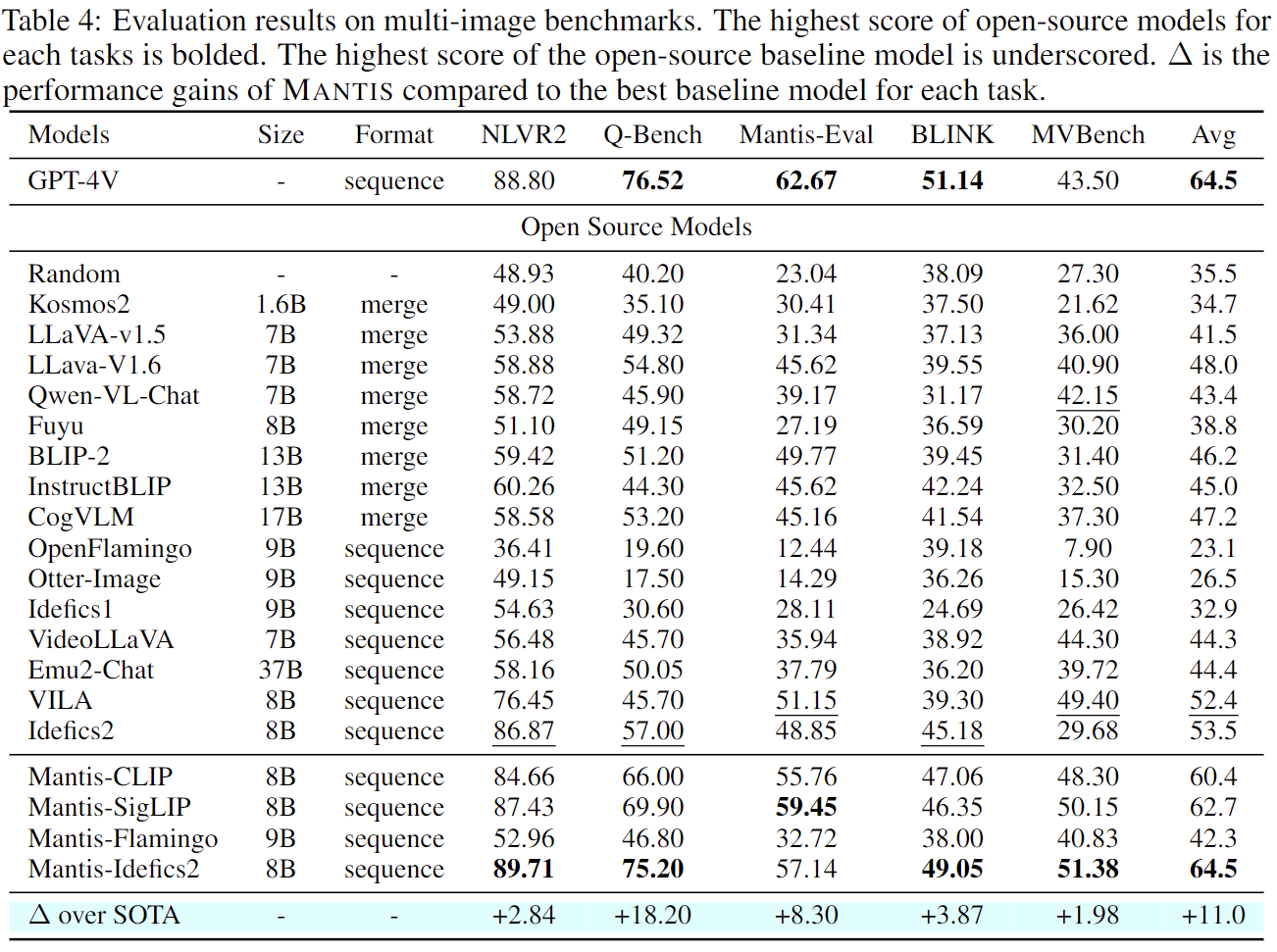
Evaluation on 5 benchmarks, including NLVR2, Q-Bench, BLINK, MVBench, Mantis-Eval, shows that Mantis achieves the state-of-the-art performance. It demonstrates that Mantis effectively learn the 4 crucial multi-image skills (co-reference, reasoning, comparing, temporal understanding) from the interleaved text-image instructions dataset, Mantis-Instruct. We have surpassed the second best Idefics2-8B (pre-trained on 140M interleaved image-text data) by an average of 9 absolute points, and is only behind GPT-4 by 2 points.
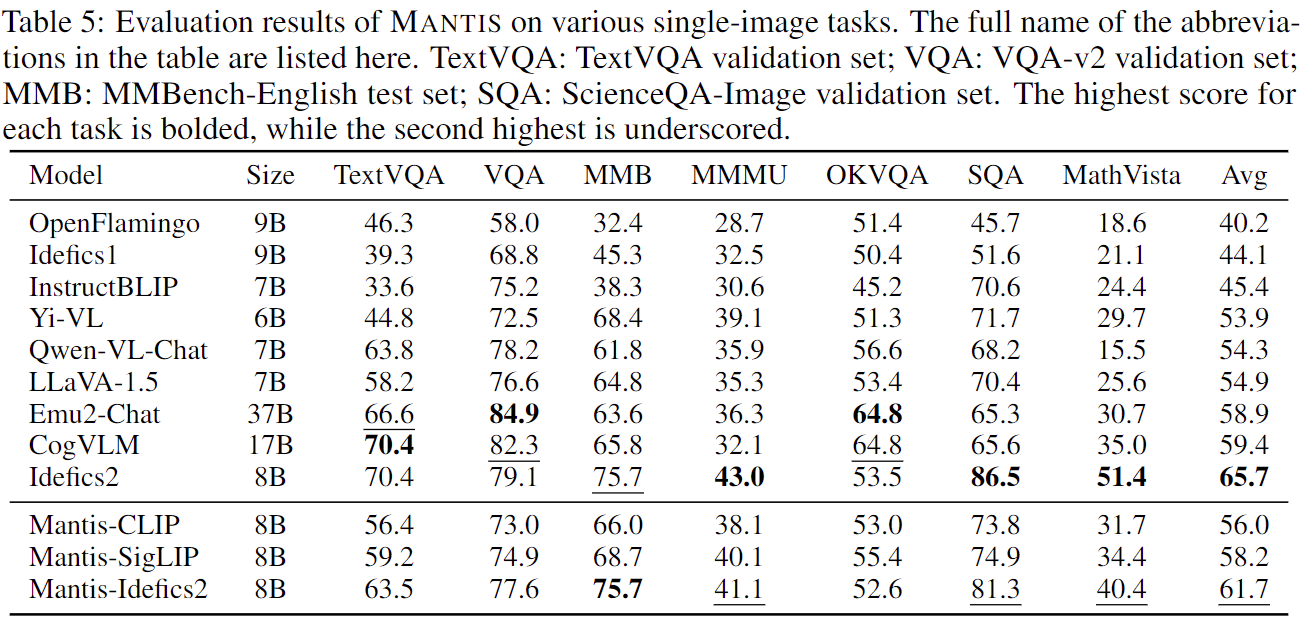
We also evaluate Mantis-8B-CLIP and Mantis-8B-SigLIP on various single-image tasks, including TextVQA, VQA-v2, MMBench, MMMU, etc. Mantis models reach on-par average performance with CogVLM, and Emu2-Chat

@inproceedings{Jiang2024MANTISIM,
title={MANTIS: Interleaved Multi-Image Instruction Tuning},
author={Dongfu Jiang and Xuan He and Huaye Zeng and Cong Wei and Max W.F. Ku and Qian Liu and Wenhu Chen},
publisher={arXiv2405.01483}
year={2024},
}