Existing information retrieval (IR) models often assume a homogeneous format, limiting their applicability to diverse user needs, such as searching for images with text descriptions, searching for a news article with a headline image, or finding a similar photo with a query image.
To approach such different information-seeking demands, we introduce UniIR![]() , a unified instruction-guided multimodal retriever capable of handling eight distinct retrieval tasks across modalities.
UniIR, a single retrieval system jointly trained on ten diverse multimodal-IR datasets, interprets user instructions to execute various retrieval tasks, demonstrating robust performance across existing datasets and zero-shot generalization to new tasks.
Our experiments highlight that multi-task training and instruction tuning are keys to UniIR's generalization ability.
Additionally, we construct the M-BEIR, a multimodal retrieval benchmark with comprehensive results, to standardize the evaluation of universal multimodal information retrieval.
, a unified instruction-guided multimodal retriever capable of handling eight distinct retrieval tasks across modalities.
UniIR, a single retrieval system jointly trained on ten diverse multimodal-IR datasets, interprets user instructions to execute various retrieval tasks, demonstrating robust performance across existing datasets and zero-shot generalization to new tasks.
Our experiments highlight that multi-task training and instruction tuning are keys to UniIR's generalization ability.
Additionally, we construct the M-BEIR, a multimodal retrieval benchmark with comprehensive results, to standardize the evaluation of universal multimodal information retrieval.
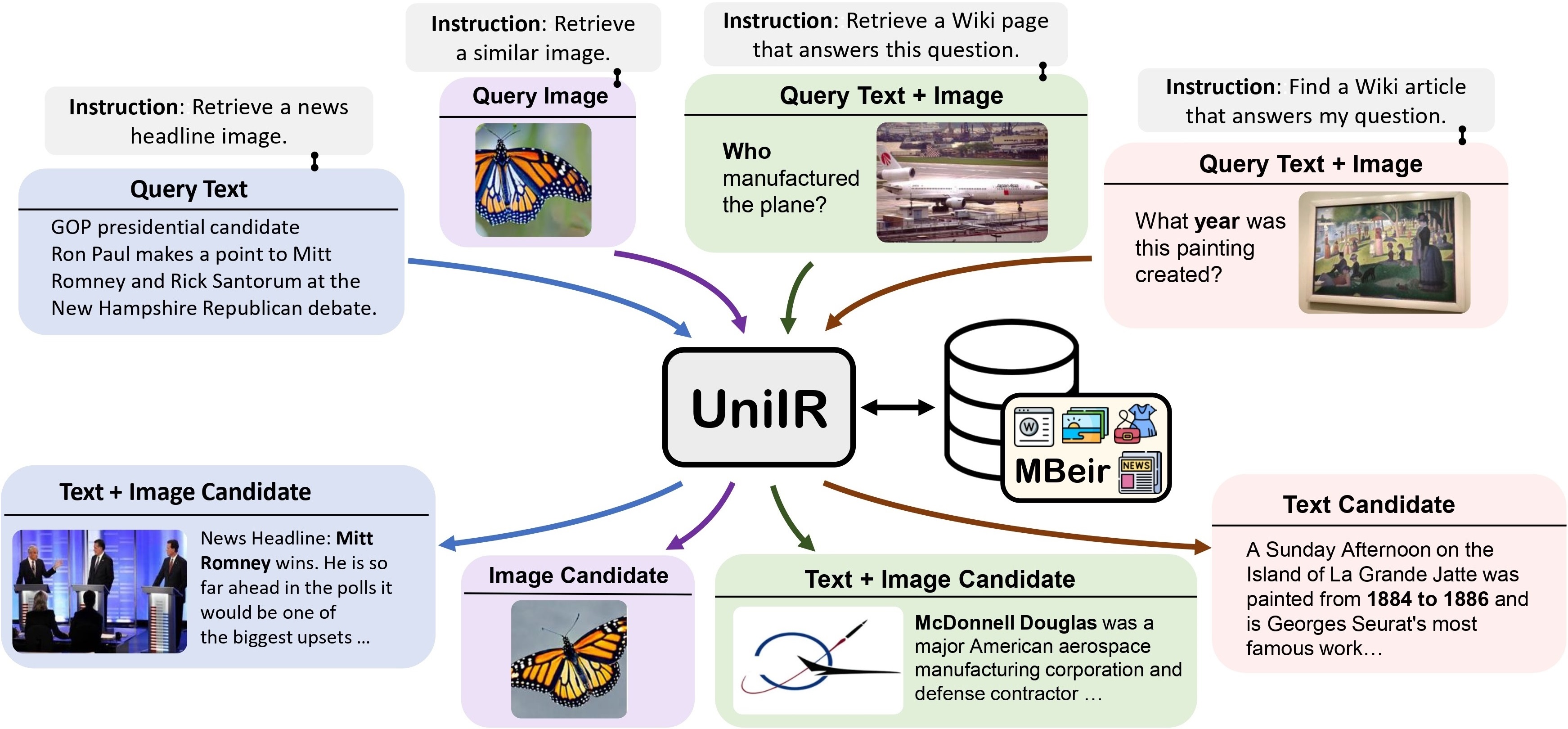
We propose the UniIR(Universal multimodal Information Retrieval) framework to learn a single retriever to accomplish (possibly) any retrieval task. Unlike traditional IR systems, UniIR needs to follow the instructions to take a heterogeneous query to retrieve from a heterogeneous candidate pool with millions of candidates in diverse modalities.

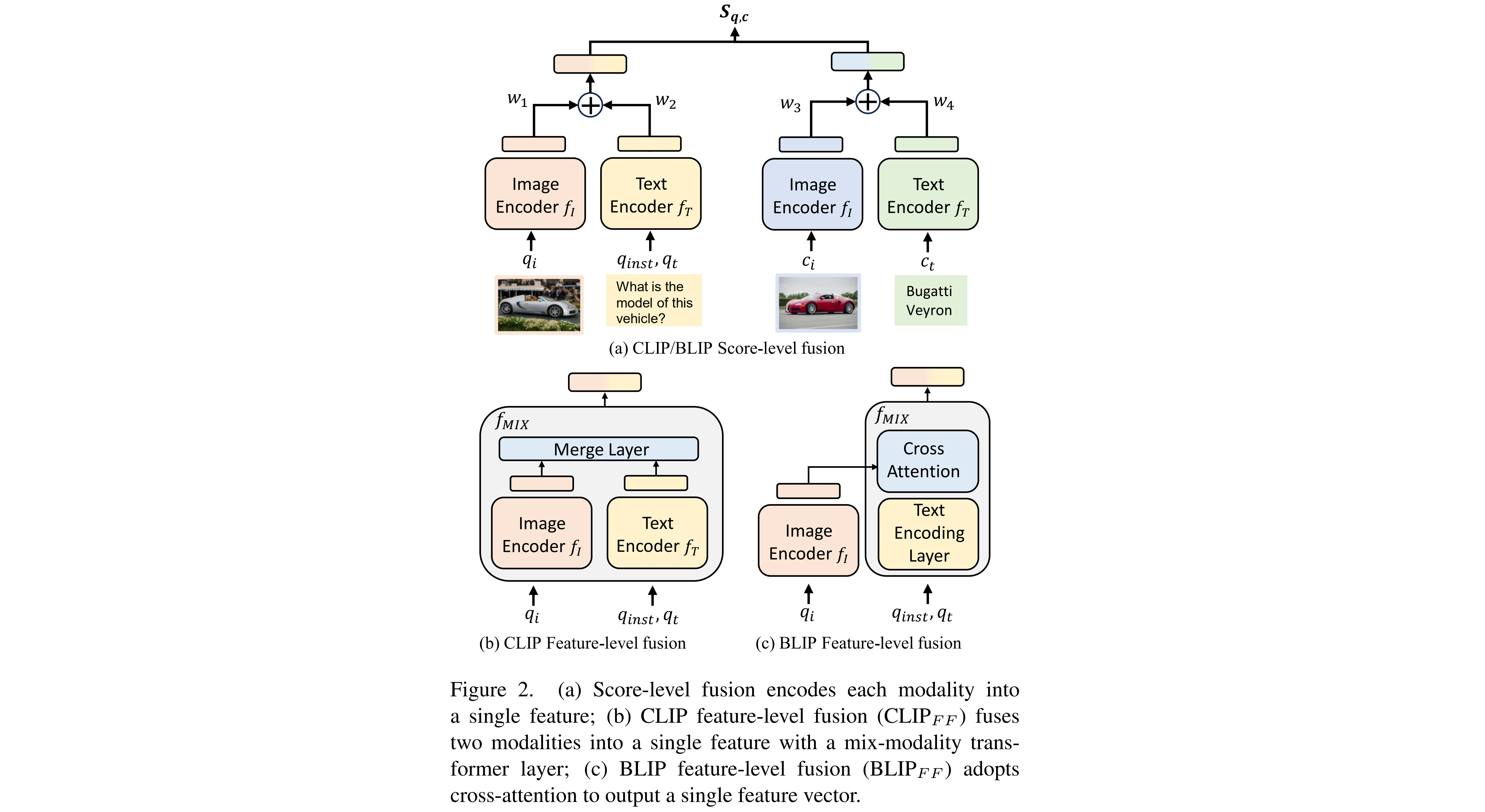
We experimented with two multimodal fusion mechanisms for UniIR models, namely score-level fusion and feature-level fusion. To explore the effectiveness of these approaches, we adapted pre-trained models such as CLIP and BLIP for our purposes as follows. Instructions were integrated as prefixes to the text query for UniIR models.
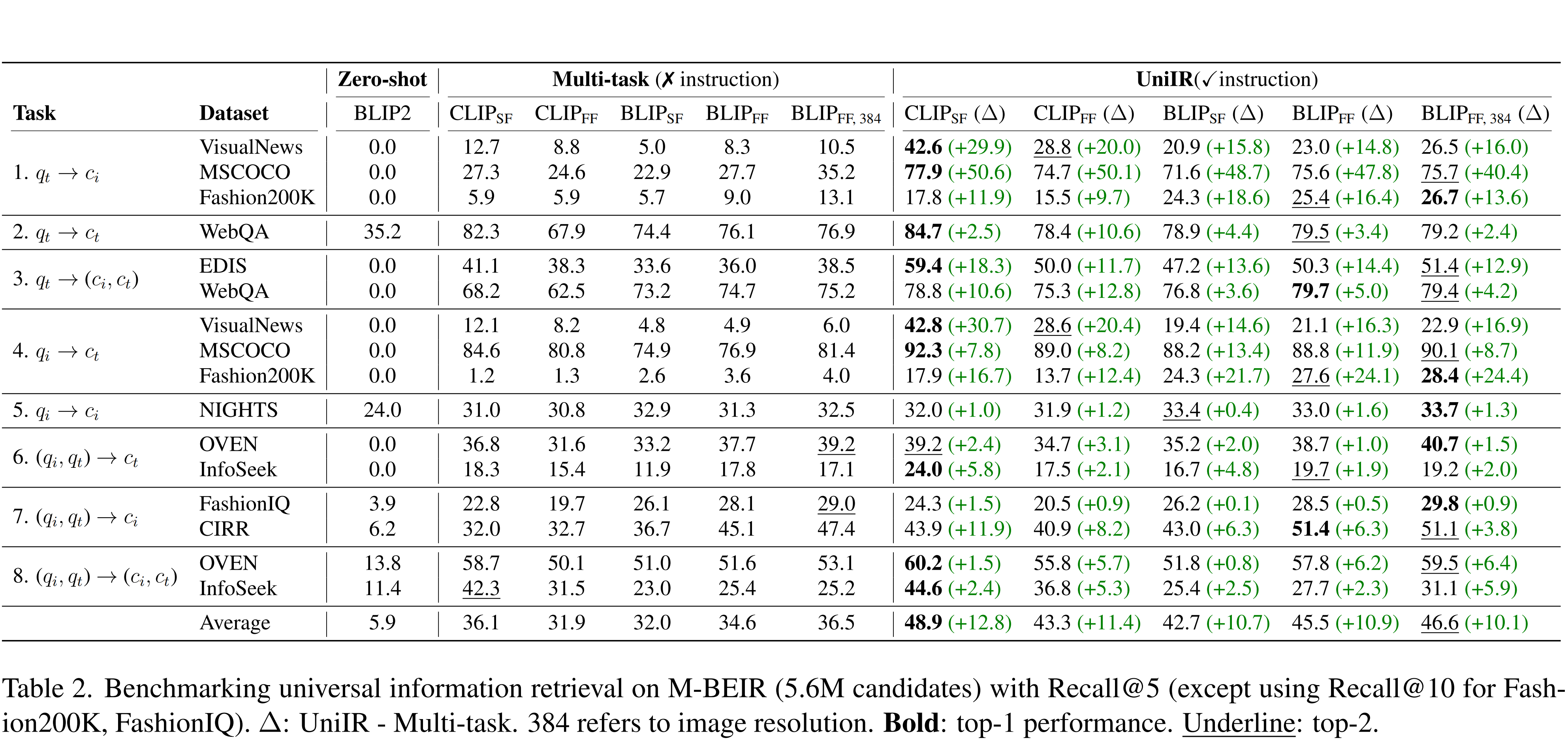
To train and evaluate unified multimodal retrieval models, we build a large-scale retrieval benchmark named M-BEIR (Multimodal BEnchmark for Instructed Retrieval). The M-BEIR benchmark comprises 8 multimodal retrieval tasks and 10 datasets from a variety of domains and image sources. Each task is accompanied by human-authored instructions, encompassing 1.5 million queries and a pool of 5.6 million retrieval candidates in total.

Our evaluation encompasses zero-shot SoTA models, multi-task fine-tuned baselines (fine-tuned jointly on all M-BEIR training data without incorporating instructions), and UniIR models. Retrieval is performed from the M-BEIR 5.6 million candidate pool, which consists of the retrieval corpus from all tasks. We demonstrate that zero-shot models struggle to retrieve queried information from such a heterogeneous pool and instruction-tuning as a crucial component of UniIR.

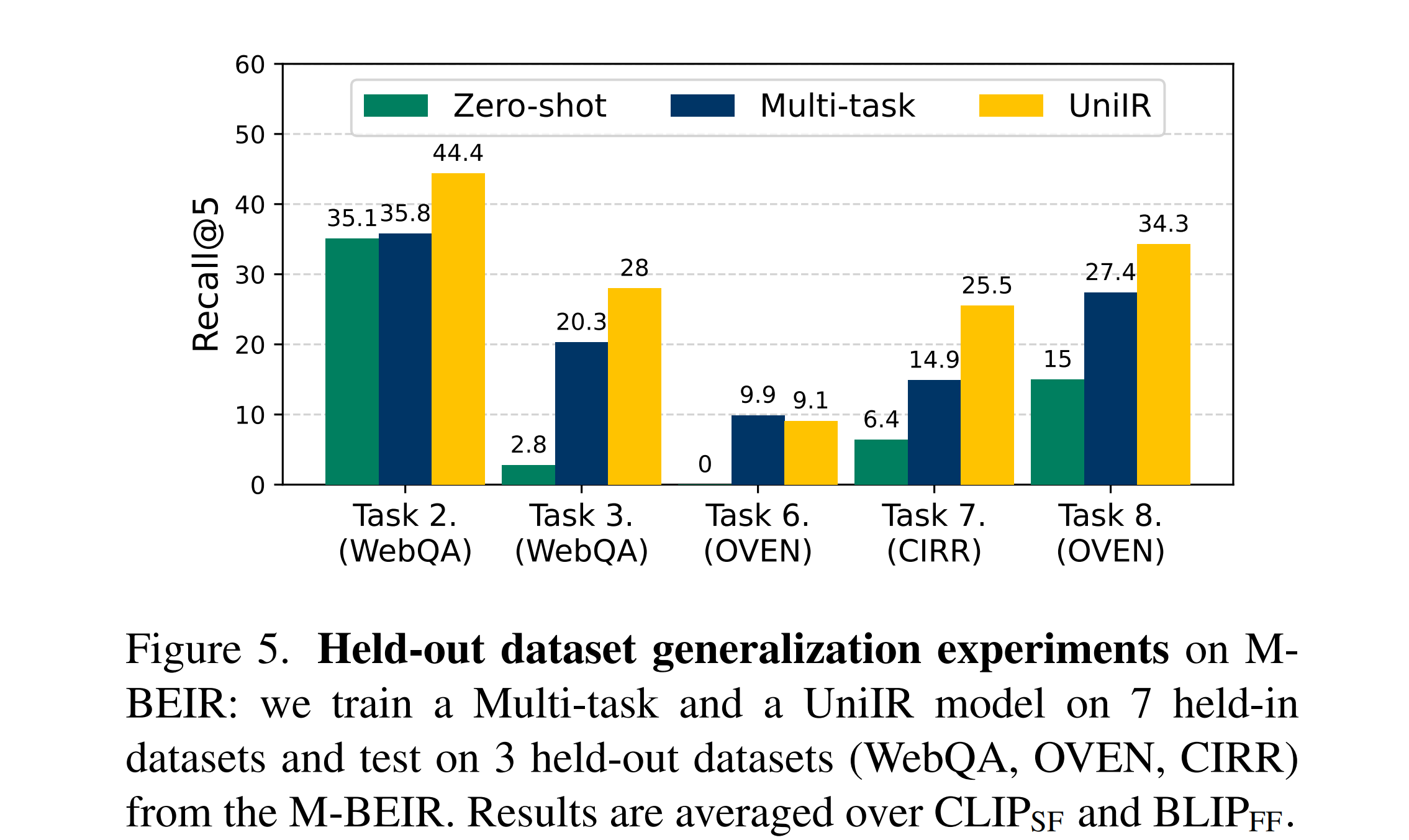
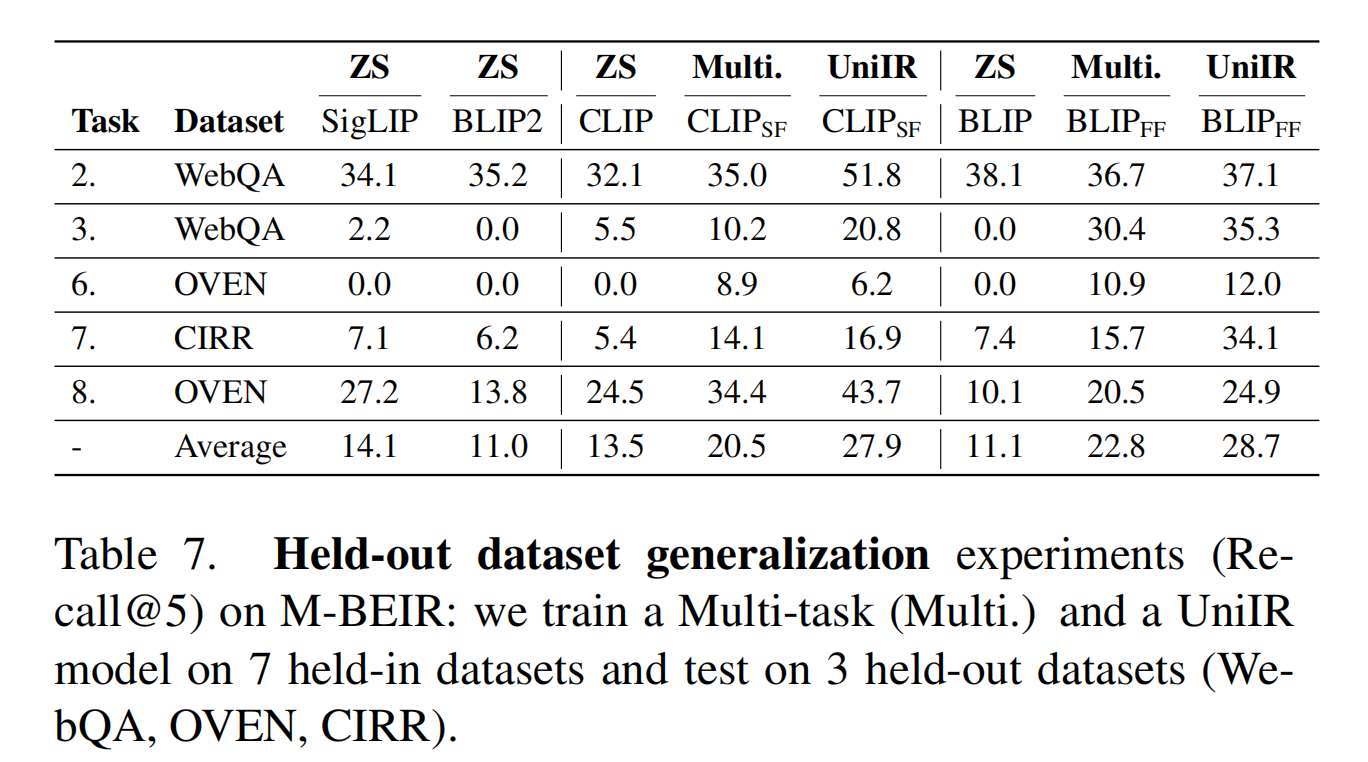
During the multi-task fine-tuning stage of UniIR, we excluded three datasets (WebQA, OVEN, CIRR) and fine-tuned UniIR models and multi-task baselines on the remaining M-BEIR datasets. At test time, we evaluated the zero-shot performance of all fine-tuned models, as well as SoTA pre-trained retrievers on the three held-out datasets. UniIR models exhibit superior generalization abilities on unseen tasks and datasets compared to baselines.
@article{wei2023uniir,
title={Uniir: Training and benchmarking universal multimodal information retrievers},
author={Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu},
journal={arXiv preprint arXiv:2311.17136},
year={2023}
}