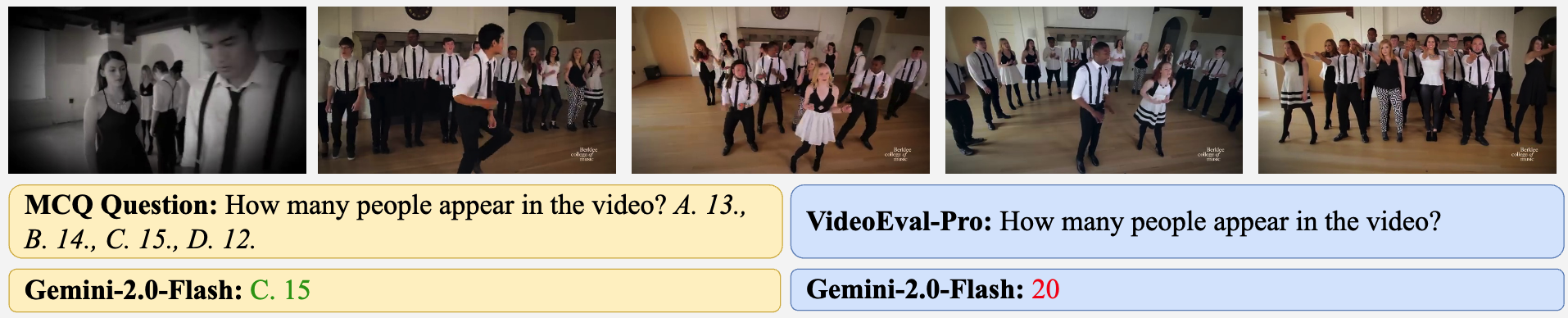
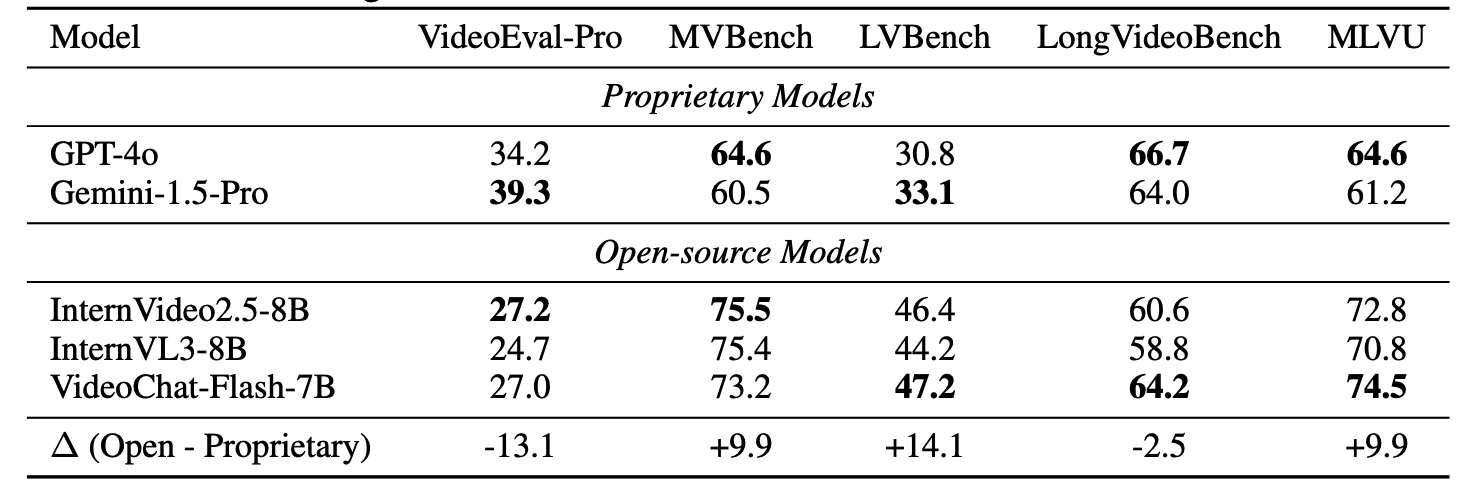
Main results of our VideoEval-Pro benchmark. For a detailed leaderboard, please click the link at the top.
∆ indicates the gap between MCQ
and open-ended questions. LP, LR, HP and HR correspond to Local Perception, Local Reasoning, Holistic Perception and Holistic Reasoning tasks.
| # | Model | LLM Params |
Frames | LP (%) | LR (%) | HP (%) | HR (%) | Overall (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open | MCQ | Open | MCQ | Open | MCQ | Open | MCQ | Open | MCQ | ∆ | ||||
|
GPT-4o
Proprietary |
- | 256 | 39.4 | 64.8 | 23.1 | 62.6 | 26.4 | 42.1 | 29.2 | 50.4 | 34.2 | 59.5 | 25.3 | |
|
Gemini-1.5-Flash
Proprietary |
- | 512 | 41.5 | 65.5 | 25.9 | 63.9 | 27.3 | 36.4 | 25.8 | 55.7 | 35.1 | 60.6 | 25.5 | |
|
Gemini-2.5-Flash
Proprietary |
- | 256 | 42.4 | 64.1 | 30.6 | 65.3 | 25.6 | 33.9 | 26.9 | 54.2 | 36.3 | 59.3 | 23.0 | |
|
Gemini-1.5-Pro
Proprietary |
- | 512 | 43.7 | 66.7 | 32.7 | 69.4 | 35.5 | 40.5 | 31.8 | 61.0 | 39.3 | 63.4 | 24.1 | |
|
GPT-4.1-mini
Proprietary |
- | 256 | 46.0 | 68.6 | 32.0 | 68.7 | 27.3 | 38.8 | 32.6 | 57.6 | 39.9 | 63.5 | 23.6 | |
|
GPT-4.1
Proprietary |
- | 256 | 47.2 | 68.8 | 29.9 | 68.7 | 28.1 | 38.0 | 34.5 | 59.5 | 40.8 | 64.0 | 23.2 | |
|
Video-LLaVA
Open-source |
8B | 8 | 13.2 | 27.5 | 6.1 | 33.3 | 14.0 | 24.8 | 6.1 | 26.5 | 11.0 | 27.7 | 16.7 | |
|
Mantis-Idefics2
Open-source |
8B | 24 | 17.8 | 33.2 | 9.5 | 29.9 | 16.5 | 16.5 | 8.3 | 29.9 | 14.8 | 30.6 | 15.8 | |
|
LongVA
Open-source |
7B | 64 | 20.5 | 43.3 | 6.8 | 33.3 | 19.0 | 24.0 | 9.5 | 31.8 | 16.5 | 38.0 | 21.5 | |
|
Phi-4-Mini
Open-source |
5.6B | 128 | 19.2 | 46.4 | 12.9 | 47.6 | 18.2 | 30.6 | 10.2 | 31.4 | 16.5 | 42.0 | 25.5 | |
|
LongLLaVA
Open-source |
9B | 512 | 21.7 | 41.2 | 15.0 | 34.0 | 14.0 | 29.8 | 10.2 | 29.2 | 17.8 | 36.9 | 19.1 | |
|
Video-XL
Open-source |
7B | 512 | 22.3 | 41.9 | 15.0 | 34.0 | 18.2 | 28.1 | 10.2 | 29.2 | 18.6 | 38.2 | 19.6 | |
|
LongVU
Open-source |
7B | 512 | 25.9 | 45.6 | 12.9 | 38.8 | 19.8 | 24.0 | 17.4 | 37.1 | 22.1 | 41.0 | 18.9 | |
|
Vamba
Open-source |
10B | 512 | 28.1 | 52.4 | 10.9 | 40.8 | 21.5 | 26.4 | 12.5 | 37.9 | 22.3 | 45.7 | 23.4 | |
|
LLaVA-Video
Open-source |
7B | 64 | 28.5 | 53.5 | 13.6 | 47.6 | 20.7 | 28.9 | 19.3 | 40.2 | 24.2 | 47.8 | 23.6 | |
|
InternVL2.5
Open-source |
8B | 64 | 28.8 | 54.3 | 19.7 | 46.3 | 21.5 | 35.5 | 16.7 | 39.0 | 24.6 | 48.5 | 23.9 | |
|
InternVL3
Open-source |
8B | 64 | 30.3 | 54.6 | 17.0 | 49.0 | 24.0 | 34.7 | 13.3 | 36.7 | 24.7 | 48.4 | 23.7 | |
|
Qwen2-VL
Open-source |
7B | 512 | 31.7 | 59.3 | 14.3 | 51.7 | 21.5 | 28.1 | 20.5 | 39.0 | 26.5 | 48.2 | 21.7 | |
|
InternVideo2.5
Open-source |
8B | 512 | 33.6 | 59.8 | 17.0 | 47.6 | 19.8 | 34.7 | 18.2 | 45.8 | 27.2 | 53.2 | 26.0 | |
|
VideoChat-Flash
Open-source |
7B | 512 | 33.3 | 57.7 | 16.3 | 43.5 | 21.5 | 33.9 | 17.4 | 44.7 | 27.0 | 51.2 | 24.2 | |
|
Qwen2.5-VL
Open-source |
7B | 512 | 33.9 | 51.7 | 15.6 | 48.3 | 24.8 | 31.4 | 17.8 | 39.8 | 27.7 | 46.9 | 19.2 | |
|
MiMo-VL-SFT
Open-source |
7B | 512 | 34.7 | 57.7 | 19.0 | 55.8 | 26.4 | 36.4 | 19.7 | 41.7 | 29.1 | 52.2 | 23.1 | |
|
MiMo-VL-RL
Open-source |
7B | 512 | 35.5 | 57.5 | 18.4 | 55.8 | 28.1 | 33.1 | 18.9 | 42.8 | 29.5 | 52.0 | 22.5 | |
|
Video-XL-2
Open-source |
8B | 512 | 33.3 | 57.6 | 25.2 | 55.1 | 21.5 | 38.8 | 20.5 | 45.1 | 28.6 | 53.0 | 24.4 | |
|
gemini-2.0-flash
Proprietary |
- | 512 | 43.6 | 69.0 | 27.9 | 58.5 | 27.3 | 42.1 | 30.7 | 53.8 | 37.6 | 62.1 | 24.5 | |
|
gemini-2.5-pro
Proprietary |
- | 512 | 47.2 | 73.3 | 35.4 | 69.4 | 41.3 | 46.3 | 42.0 | 67.4 | 44.2 | 69.1 | 24.9 | |
|
internvl3.5
Open-source |
8B | 128 | 28.4 | 55.5 | 20.4 | 58.5 | 20.7 | 38.0 | 17.0 | 36.7 | 24.4 | 50.3 | 25.9 | |
|
KeyeVL
Open-source |
8B | 64 | 18.9 | 45.4 | 11.6 | 46.3 | 19.0 | 32.2 | 9.5 | 32.2 | 16.1 | 41.6 | 25.5 | |
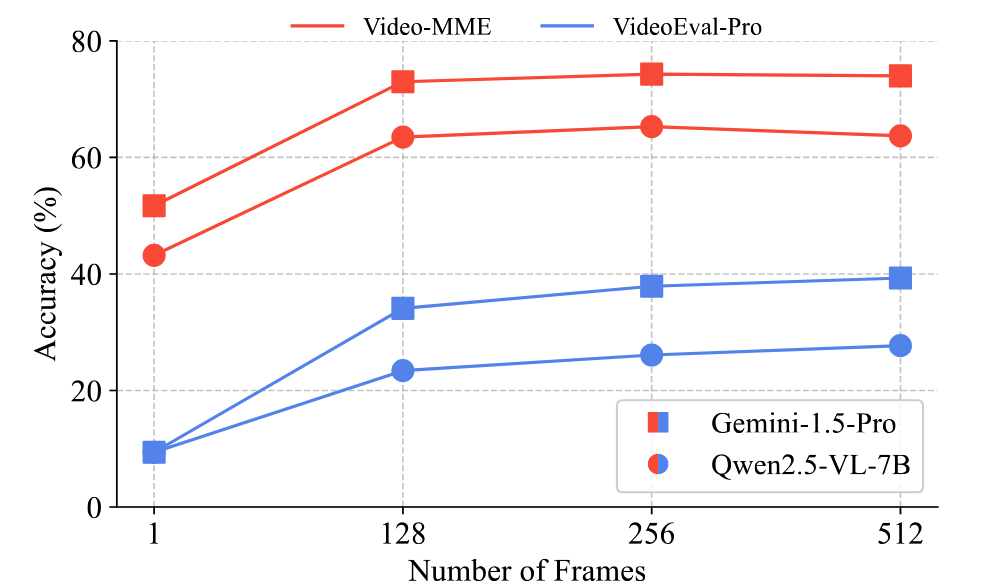
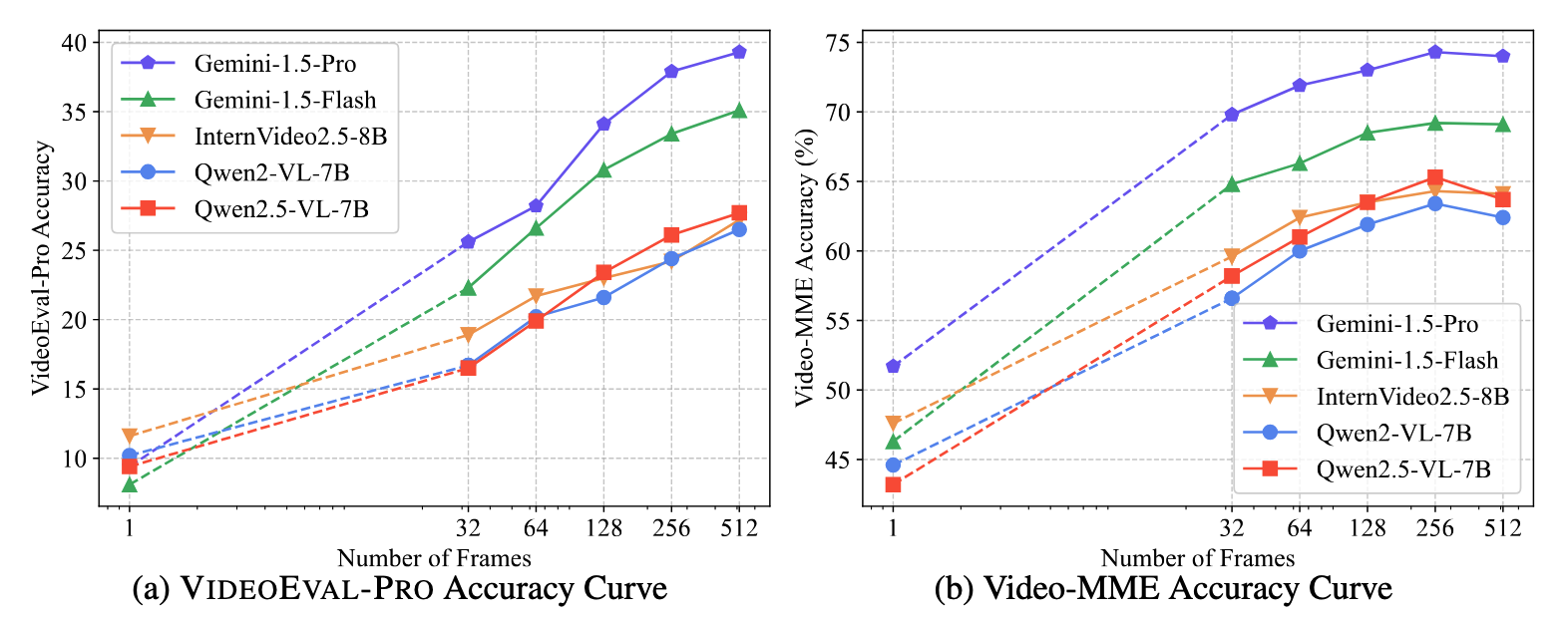
* As different candidate models are trained using different numbers of frames, we evaluate each one with inputs of 32, 64, 128, 256, and 512 frames and report its highest score. If a model cannot handle larger inputs (e.g. due to API restrictions or model context length limits), we instead report its best score among the frame counts that fit within its allowable context window