- MAmmoTH-VL2 achieves state-of-the-art performance in 5 out of 7 benchmarks among all open-source models in the 7B-11B parameter range
- On MMMU-Pro standard, our model shows 40.7% accuracy, outperforming all other open-source models
- Particularly strong performance on mathematical reasoning benchmarks, with significant improvements on MathVerse (+3.1% over SoTA) and Dyna-Math (+4.3% over SoTA)
- Overall average performance of 50.4% represents a +1.7% improvement over the previous state-of-the-art
- Performance gap with closed-source models has been significantly narrowed, especially on specialized reasoning tasks
Overview
VisualWebInstruct is a novel approach to create large-scale, high-quality multimodal reasoning datasets without expensive human annotation. By leveraging Google Image Search, we build a comprehensive dataset spanning multiple disciplines that enhances vision-language models' reasoning capabilities.
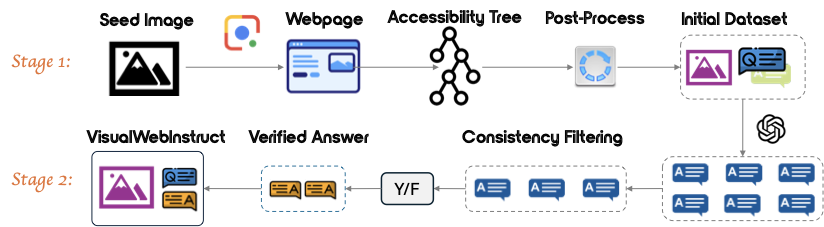
Our approach addresses a critical bottleneck in visual reasoning models by enabling the creation of diverse instruction data spanning mathematics, physics, chemistry, finance, and more.