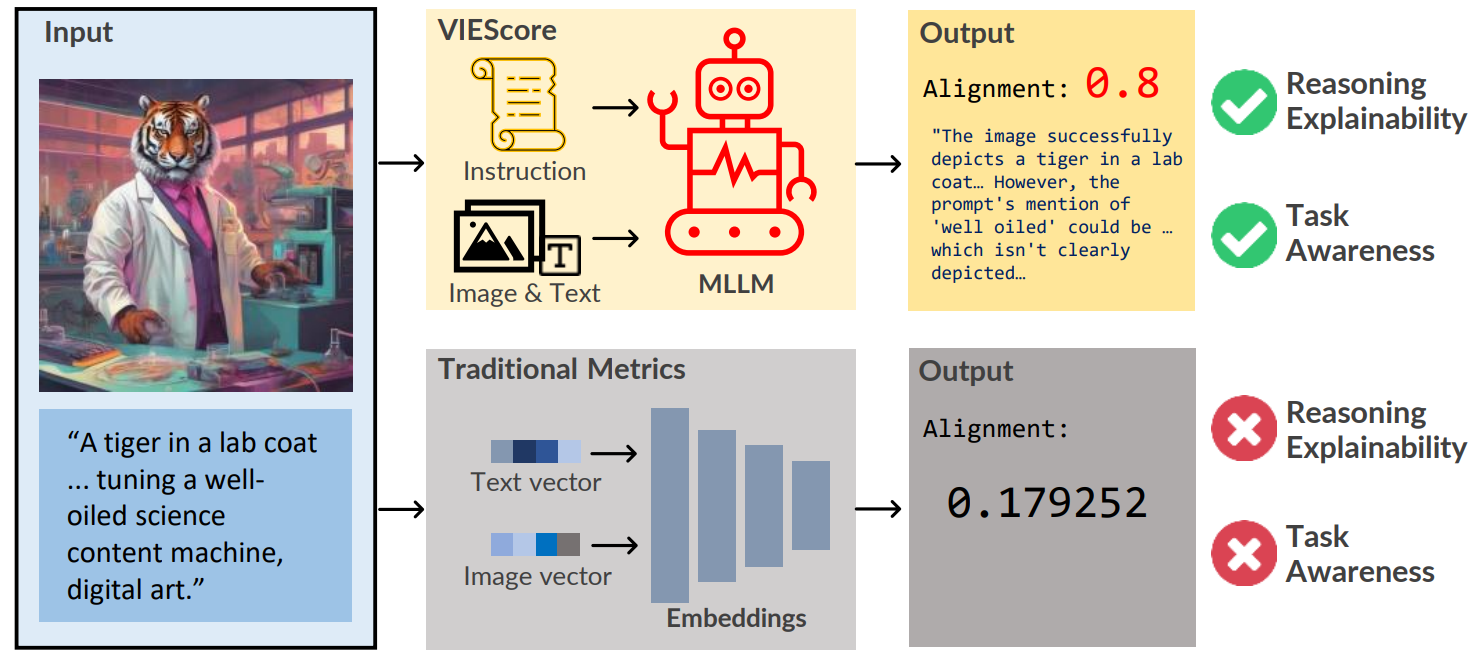
In the rapidly advancing field of conditional image generation research, challenges such as limited explainability lie in effectively evaluating the performance and capabilities of various models. This paper introduces VIEScore, a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks. VIEScore leverages general knowledge from Multimodal Large Language Models (MLLMs) as the backbone and does not require training or fine-tuning. We evaluate VIEScore on seven prominent tasks in conditional image tasks and found: (1) VIEScore (GPT4-o) achieves a high Spearman correlation of 0.4 with human evaluations, while the human-to-human correlation is 0.45. (2) VIEScore (with open-source MLLM) is significantly weaker than GPT-4o and GPT-4v in evaluating synthetic images. (3) VIEScore achieves a correlation on par with human ratings in the generation tasks but struggles in editing tasks. With these results, we believe VIEScore shows its great potential to replace human judges in evaluating image synthesis tasks.
Traditional metrics lack task awareness! It also lacks reasoning ability. VIEScore tackles both downsides. In VIEScore, All input conditions, synthesized images, and rating instructions are fed together to the MLLM in one pass. Then we retrieve the score in any scale and the rationale.
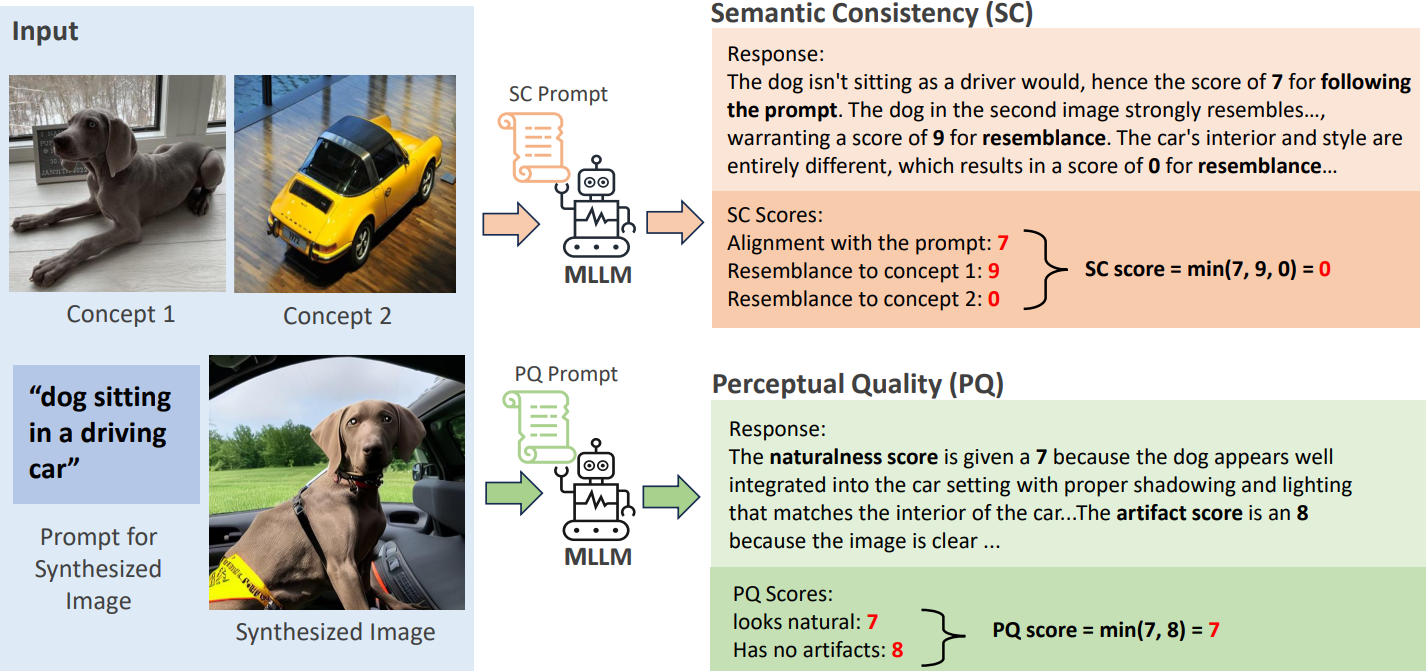
To evaluate the effectiveness of our method, we used the 7 conditional Image generation tasks from ImagenHub and computed the correlation with human ratings collected in ImagenHub.
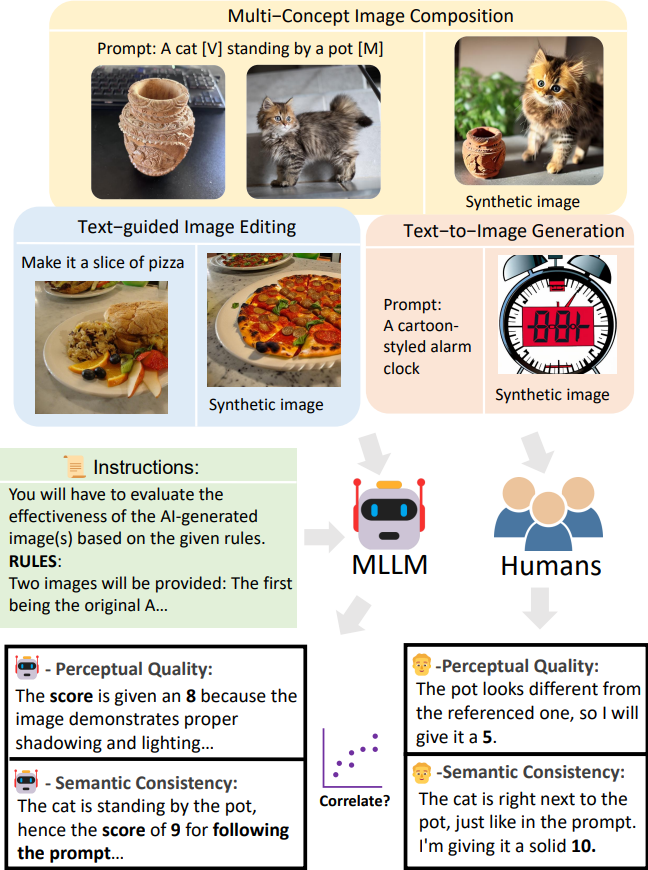
But how well can Multimodal large language models access different tasks of conditional Image generation? We reported that the best model GPT4v’s performance is significantly better than the open-source models. Most open-source MLLMs failed to adapt to our VieScore except LLaVA.
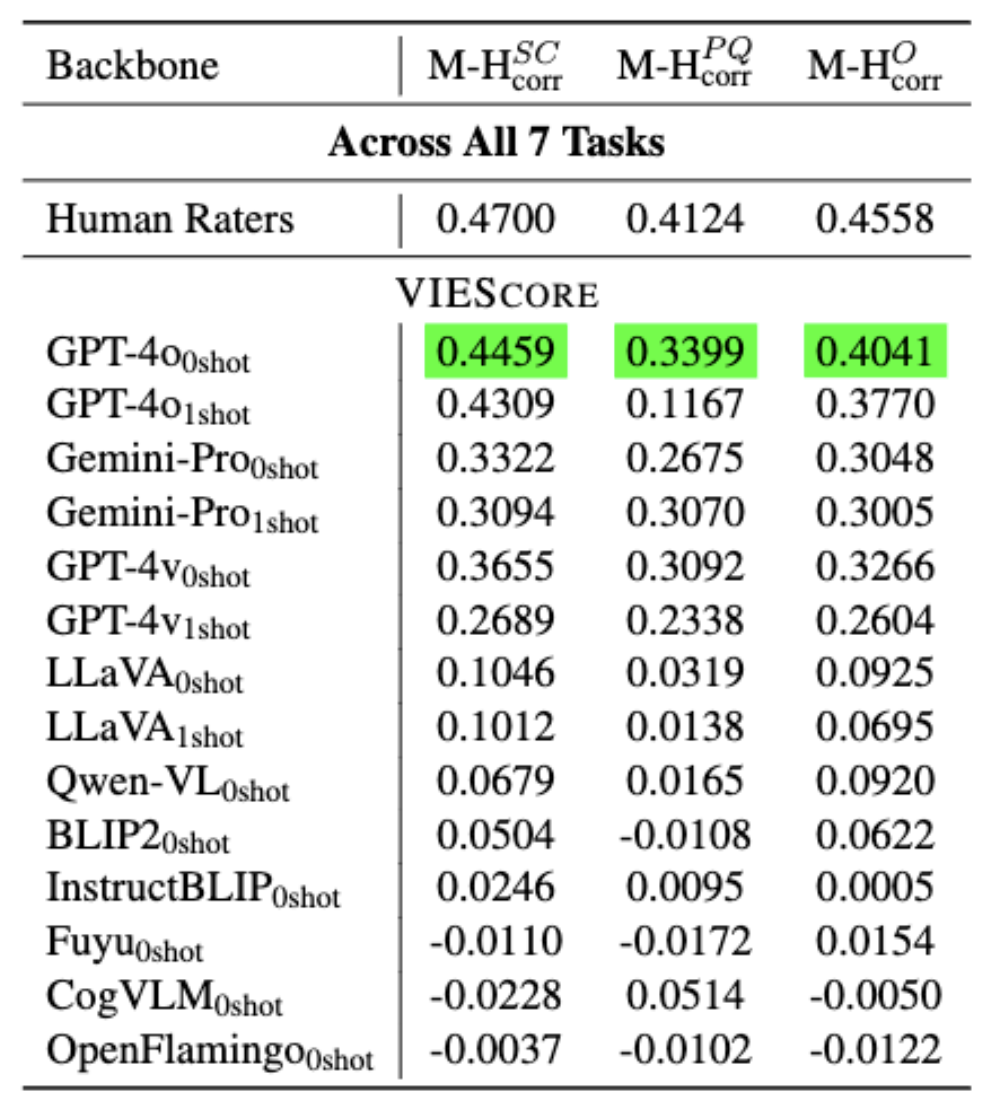
Looking into the details, we found that GPT4v achieves on par with human ratings on text-to-image task but it straggles on image editing tasks. We also compared with the traditional metrics.
| Method | Method-HumanSCcorr | Method-HumanPQcorr | Method-HumanOcorr | ||
|---|---|---|---|---|---|
| Text-guided Image Generation Model (5 models) | |||||
| Human Raters | - | Unknown | 0.5044 | 0.3640 | 0.4652 |
| CLIP-Score | -0.0817 | -0.0114 | -0.0881 | ||
| VIEScore(GPT-4o0shot) | 0.4989 | 0.2495 | 0.3928 | ||
| VIEScore(GPT-4o1shot) | 0.5124 | 0.0336 | 0.4042 | ||
| VIEScore(Gemini-Pro0shot) | 0.5123 | 0.1842 | 0.4356 | ||
| VIEScore(Gemini-Pro1shot) | 0.4757 | 0.2206 | 0.4326 | ||
| VIEScore(GPT-4v0shot) | 0.4885 | 0.2379 | 0.4614 | ||
| VIEScore(GPT-4v1shot) | 0.4531 | 0.1770 | 0.3801 | ||
| VIEScore(LLaVA0shot) | 0.1809 | 0.0306 | 0.1410 | ||
| VIEScore(LLaVA1shot) | 0.1789 | -0.0020 | 0.1309 | ||
| Mask-guided Image Editing Model (4 models) | |||||
| Human Raters | 0.5390 | 0.5030 | 0.4981 | ||
| LPIPS | -0.1012 | 0.0646 | -0.0694 | ||
| VIEScore(GPT-4o0shot) | 0.5421 | 0.3469 | 0.4769 | ||
| VIEScore(GPT-4o1shot) | 0.5246 | 0.1272 | 0.4432 | ||
| VIEScore(Gemini-Pro0shot) | 0.4304 | 0.2839 | 0.3593 | ||
| VIEScore(Gemini-Pro1shot) | 0.4595 | 0.3170 | 0.4017 | ||
| VIEScore(GPT-4v0shot) | 0.4508 | 0.2859 | 0.4069 | ||
| VIEScore(GPT-4v1shot) | 0.4088 | 0.2352 | 0.3810 | ||
| VIEScore(LLaVA0shot) | 0.1180 | -0.0531 | 0.0675 | ||
| VIEScore(LLaVA1shot) | 0.1263 | -0.0145 | 0.1040 | ||
| Text-guided Image Editing Model (8 models) | |||||
| Human Raters | 0.4230 | 0.5052 | 0.4184 | ||
| LPIPS | 0.0956 | 0.2504 | 0.1142 | ||
| VIEScore(GPT-4o0shot) | 0.4062 | 0.4863 | 0.3821 | ||
| VIEScore(GPT-4o1shot) | 0.3684 | 0.1939 | 0.3438 | ||
| VIEScore(Gemini-Pro0shot) | 0.2836 | 0.4291 | 0.2728 | ||
| VIEScore(Gemini-Pro1shot) | 0.2805 | 0.4657 | 0.2648 | ||
| VIEScore(GPT-4v0shot) | 0.2610 | 0.4274 | 0.2456 | ||
| VIEScore(GPT-4v1shot) | 0.2428 | 0.3402 | 0.2279 | ||
| VIEScore(LLaVA0shot) | 0.0448 | 0.0583 | 0.0273 | ||
| VIEScore(LLaVA1shot) | 0.0185 | -0.0107 | 0.0258 | ||
| Subject-driven Image Generation Model (4 models) | |||||
| Human Raters | 0.4780 | 0.3565 | 0.4653 | ||
| DINO | 0.4160 | 0.1206 | 0.4246 | ||
| CLIP-I | 0.2961 | 0.1694 | 0.3058 | ||
| VIEScore(GPT-4o0shot) | 0.4806 | 0.2576 | 0.4637 | ||
| VIEScore(GPT-4o1shot) | 0.4685 | -0.0171 | 0.4292 | ||
| VIEScore(Gemini-Pro0shot) | 0.2906 | 0.1765 | 0.2851 | ||
| VIEScore(Gemini-Pro1shot) | 0.3486 | 0.2800 | 0.3342 | ||
| VIEScore(GPT-4v0shot) | 0.3979 | 0.1903 | 0.3738 | ||
| VIEScore(GPT-4v1shot) | 0.2757 | 0.2261 | 0.2753 | ||
| VIEScore(LLaVA0shot) | 0.0326 | -0.0303 | 0.1219 | ||
| VIEScore(LLaVA1shot) | 0.1334 | 0.0858 | 0.1248 | ||
| Subject-driven Image Editing Model (3 models) | |||||
| Human Raters | 0.4887 | 0.2986 | 0.4747 | ||
| DINO | 0.3022 | -0.0381 | 0.3005 | ||
| CLIP-I | 0.2834 | 0.1248 | 0.2813 | ||
| VIEScore(GPT-4o0shot) | 0.4800 | 0.3734 | 0.3268 | ||
| VIEScore(GPT-4o1shot) | 0.3862 | 0.1273 | 0.3268 | ||
| VIEScore(Gemini-Pro0shot) | 0.2187 | 0.3148 | 0.2234 | ||
| VIEScore(Gemini-Pro1shot) | -0.0083 | 0.3181 | 0.0004 | ||
| VIEScore(GPT-4v0shot) | 0.3274 | 0.2960 | 0.1507 | ||
| VIEScore(GPT-4v1shot) | -0.0255 | 0.1572 | -0.0139 | ||
| VIEScore(LLaVA0shot) | 0.0360 | -0.0073 | 0.0168 | ||
| VIEScore(LLaVA1shot) | 0.0587 | -0.0249 | 0.0309 | ||
| Multi-concept Image Composition Model (3 models) | |||||
| Human Raters | 0.5927 | 0.5145 | 0.5919 | ||
| DINO | 0.0979 | -0.1643 | 0.0958 | ||
| CLIP-I | 0.1512 | -0.0963 | 0.1498 | ||
| VIEScore(GPT-4o0shot) | 0.4516 | 0.2751 | 0.4136 | ||
| VIEScore(GPT-4o1shot) | 0.4120 | -0.0141 | 0.3523 | ||
| VIEScore(Gemini-Pro0shot) | 0.3557 | 0.1948 | 0.3314 | ||
| VIEScore(Gemini-Pro1shot) | 0.4151 | 0.1798 | 0.4131 | ||
| VIEScore(GPT-4v0shot) | 0.3209 | 0.3025 | 0.3346 | ||
| VIEScore(GPT-4v1shot) | 0.1859 | 0.1185 | 0.1918 | ||
| VIEScore(LLaVA0shot) | 0.1022 | 0.1194 | 0.1070 | ||
| VIEScore(LLaVA1shot) | 0.0828 | 0.0379 | 0.0293 | ||
| Control-guided Image Generation Model (2 models) | |||||
| Human Raters | 0.5443 | 0.5279 | 0.5307 | ||
| LPIPS | 0.3699 | 0.4204 | 0.4133 | ||
| VIEScore(GPT-4o0shot) | 0.4972 | 0.4892 | 0.5439 | ||
| VIEScore(GPT-4o1shot) | 0.5544 | 0.3699 | 0.5238 | ||
| VIEScore(Gemini-Pro0shot) | 0.3254 | 0.3359 | 0.2960 | ||
| VIEScore(Gemini-Pro1shot) | 0.2677 | 0.4392 | 0.3240 | ||
| VIEScore(GPT-4v0shot) | 0.4360 | 0.4975 | 0.3999 | ||
| VIEScore(GPT-4v1shot) | 0.3892 | 0.4132 | 0.4237 | ||
| VIEScore(LLaVA0shot) | 0.2207 | 0.1060 | 0.1679 | ||
| VIEScore(LLaVA1shot) | 0.1121 | 0.0247 | 0.0416 | ||
Table 2: Correlations comparison of available methods. We highlight the best method and the correlation numbers closest to human raters. To conclude, VIEScore is the best metric in evaluating synthetic images across all tasks with high potential. DINO on the other hand proves to be an effective metric in Subject-Driven image generation and editing tasks.
Why MLLMs struggle on rating image editing tasks? This marked the disability of MLLM’s evaluation on multiple images, as MLLMs are often confused with multiple images, such as failing to spot the difference between two images. But we believe VieScore will be a mainstream evaluation method in the near future, as in practice multiple image QA is an area coming with many applications and the MLLMs will be improved in the future.


@misc{ku2023viescore,
title={VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation},
author={Max Ku and Dongfu Jiang and Cong Wei and Xiang Yue and Wenhu Chen},
year={2023},
eprint={2312.14867},
archivePrefix={arXiv},
primaryClass={cs.CV}
}