[2024-10-18]: Data and evaluation code are available. We will keep adding the evaluation pipeline for more models.
[2024-10-14]: Paper released on arXiv.
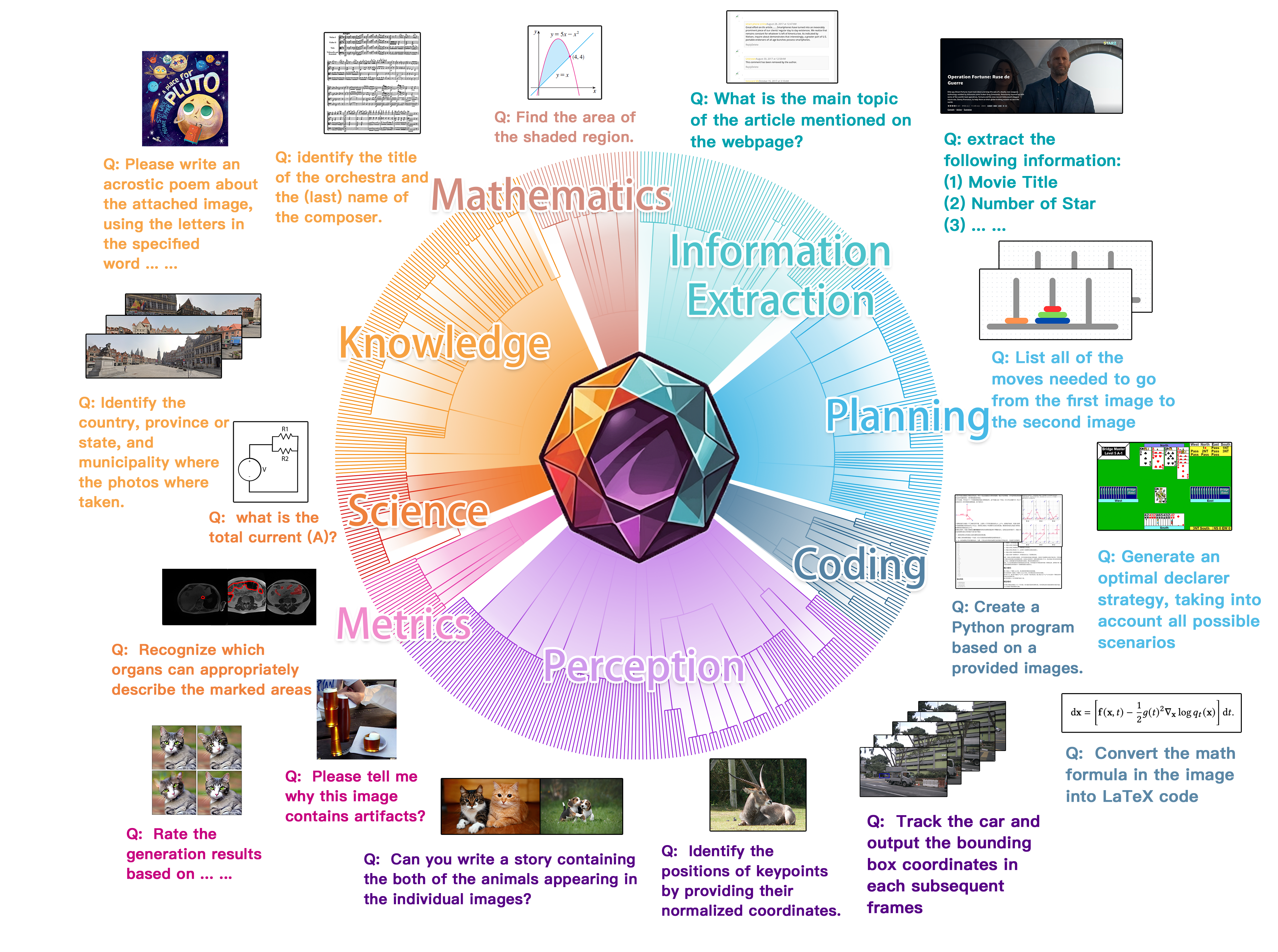
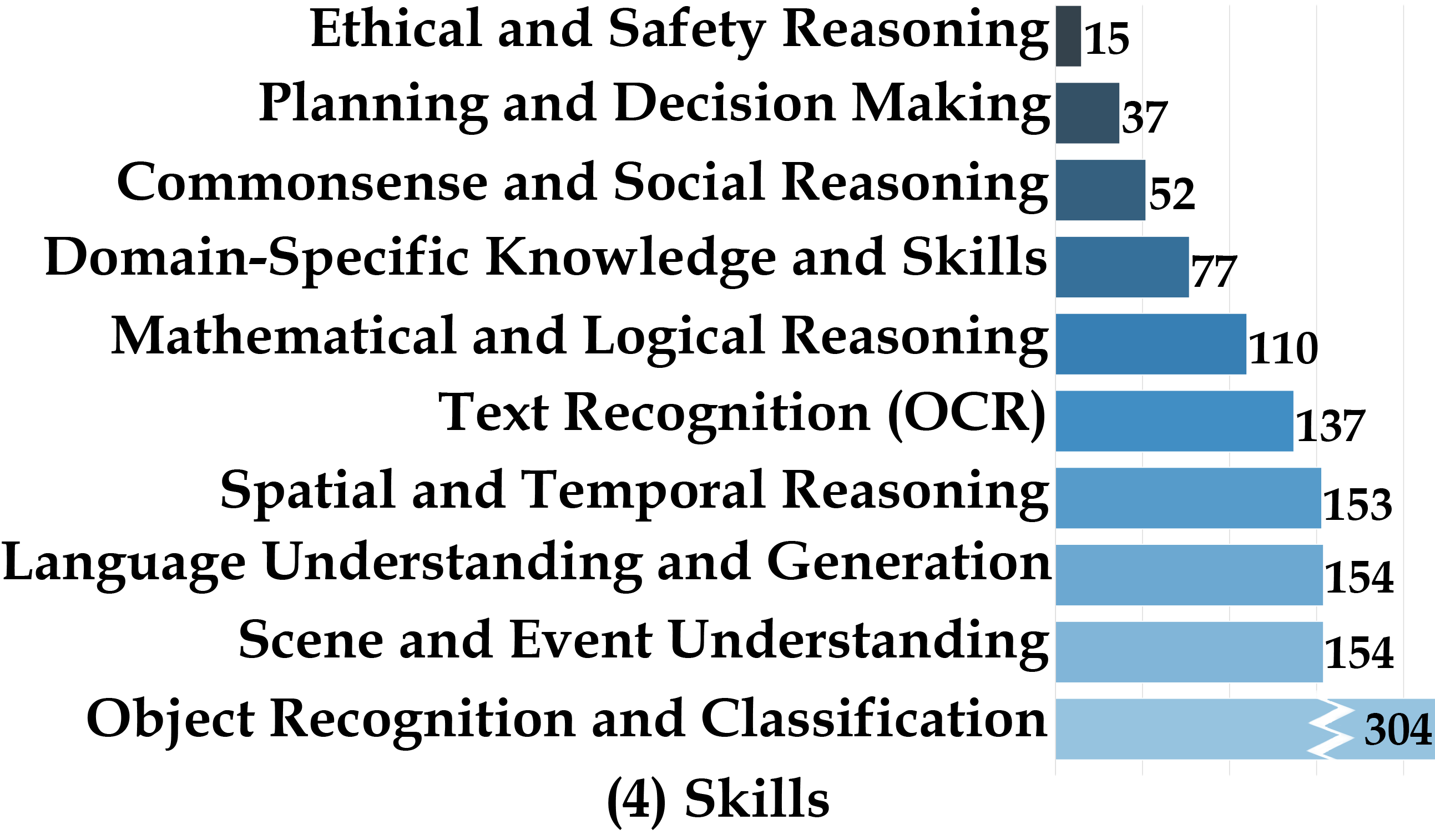
We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \( \LaTeX \), coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, input/output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
Navigate through our application-based task taxonomy to inspect the tasks!
Click the leaf node to view the detailed task information with a concrete example.
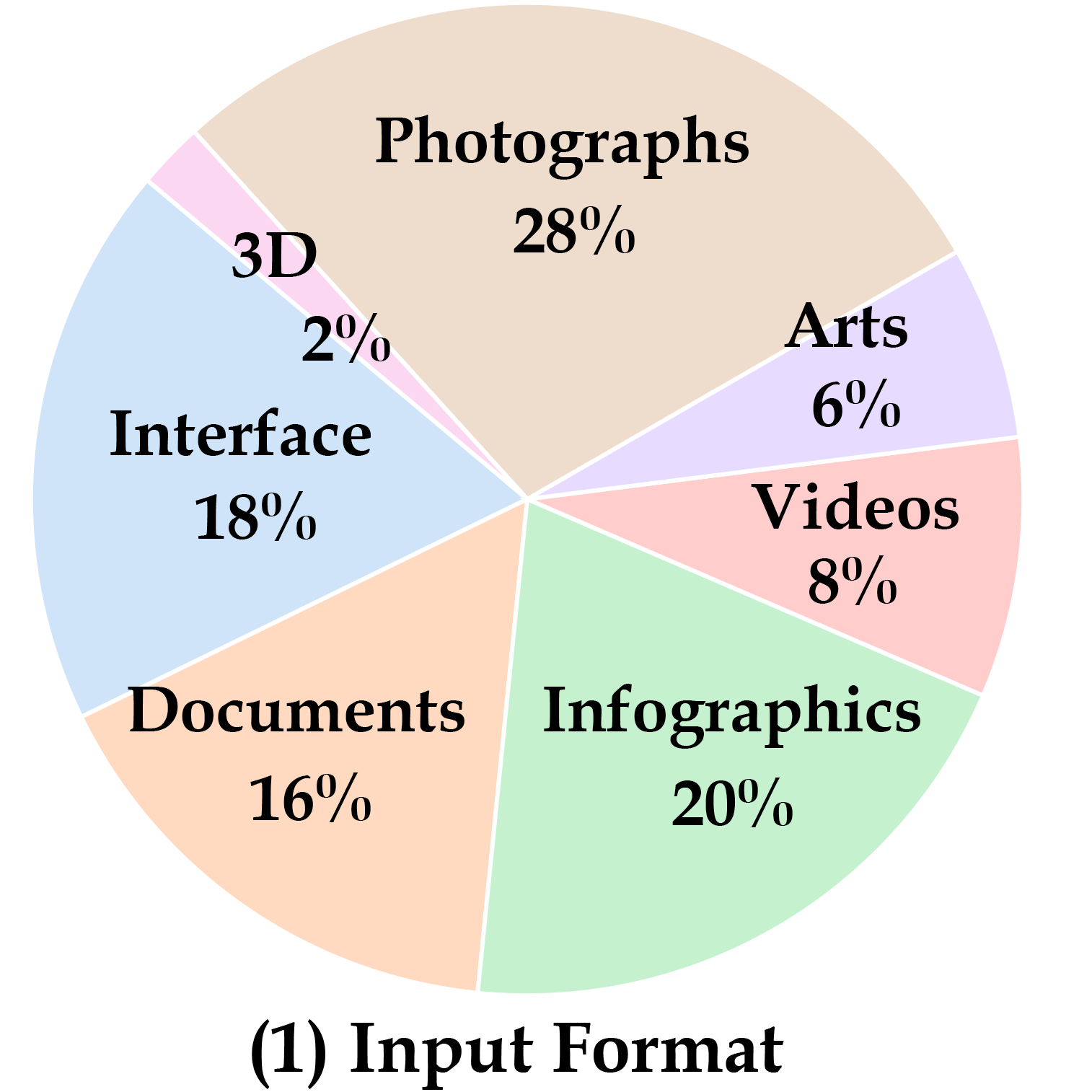
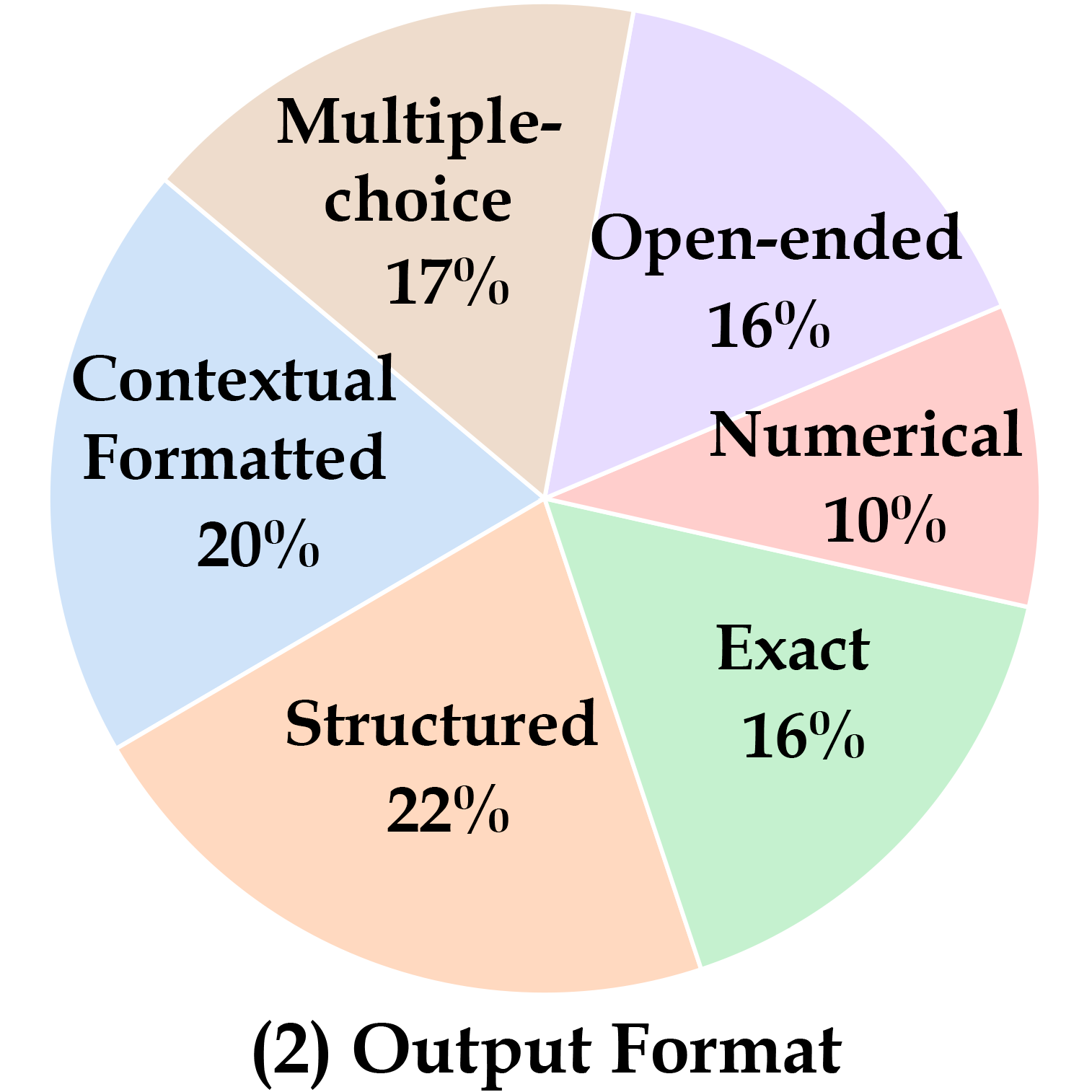
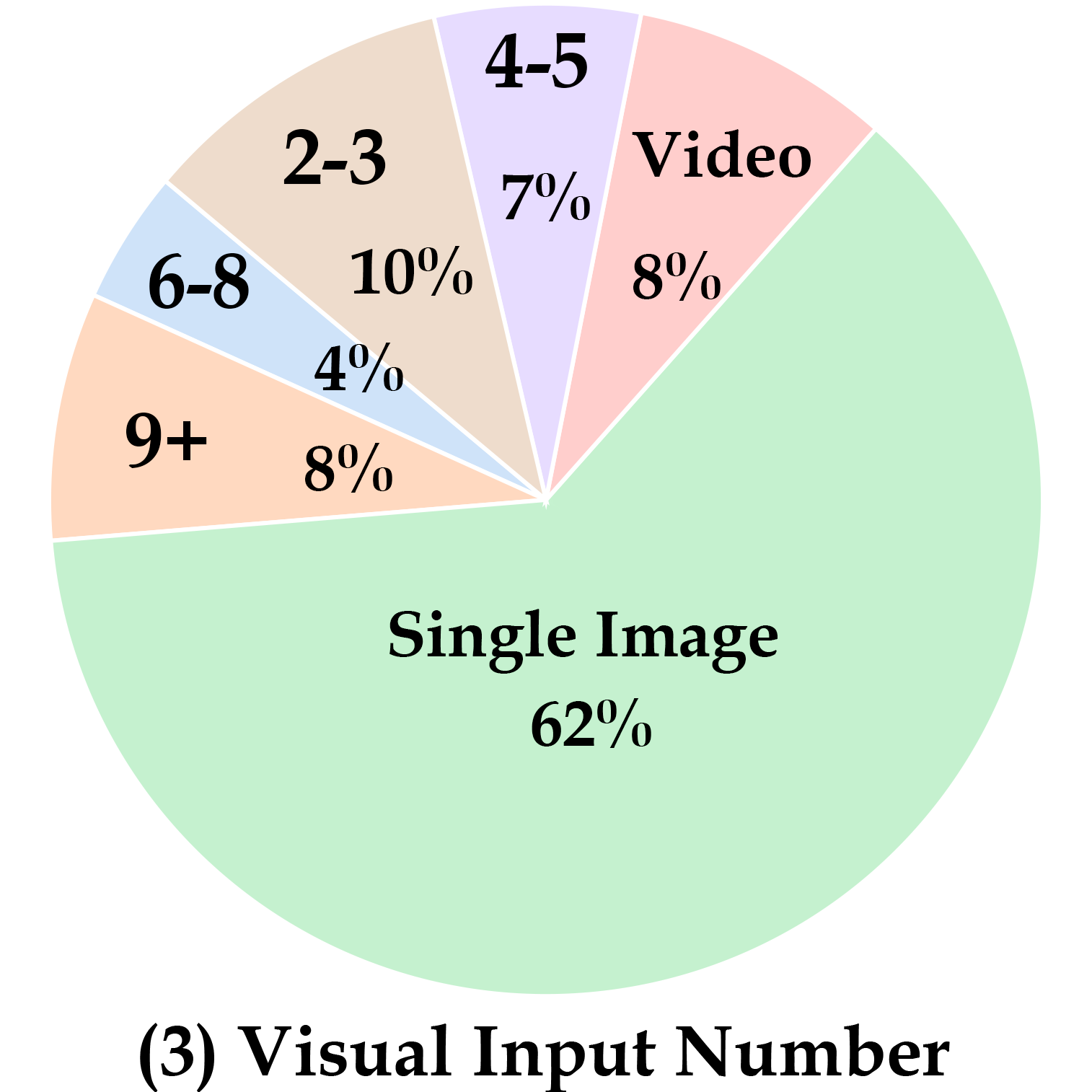
Choose from the five dimensions and pre-defined model set. Click the model name to toggle display/hide it from the radar map. We also provide a page to show all the details of a single model and compare it with a reference model (Click the "Detailed Model Report" button).
Please see our full leaderboard with detailed breakdown results at MEGA-Bench HF Spaces. Below is a preview of the leaderboard with only the summary scores.
To understand the limitations of state-of-the-art VLMs, we analyze the GPT-4o (0513) results by manually identifying the error types over a subset of 255 tasks from the Core set of MEGA-Bench. We use the results with Chain-of-Thought prompting (See details in the paper) since the reasoning process helps determine the error type. For GPT-4o, the lack of various reasoning capabilities (e.g., symbolic reasoning for planning/coding tasks, spatial or temporal reasoning for complex perception tasks, etc.) is the dominating failure mode on MEGA-Bench.
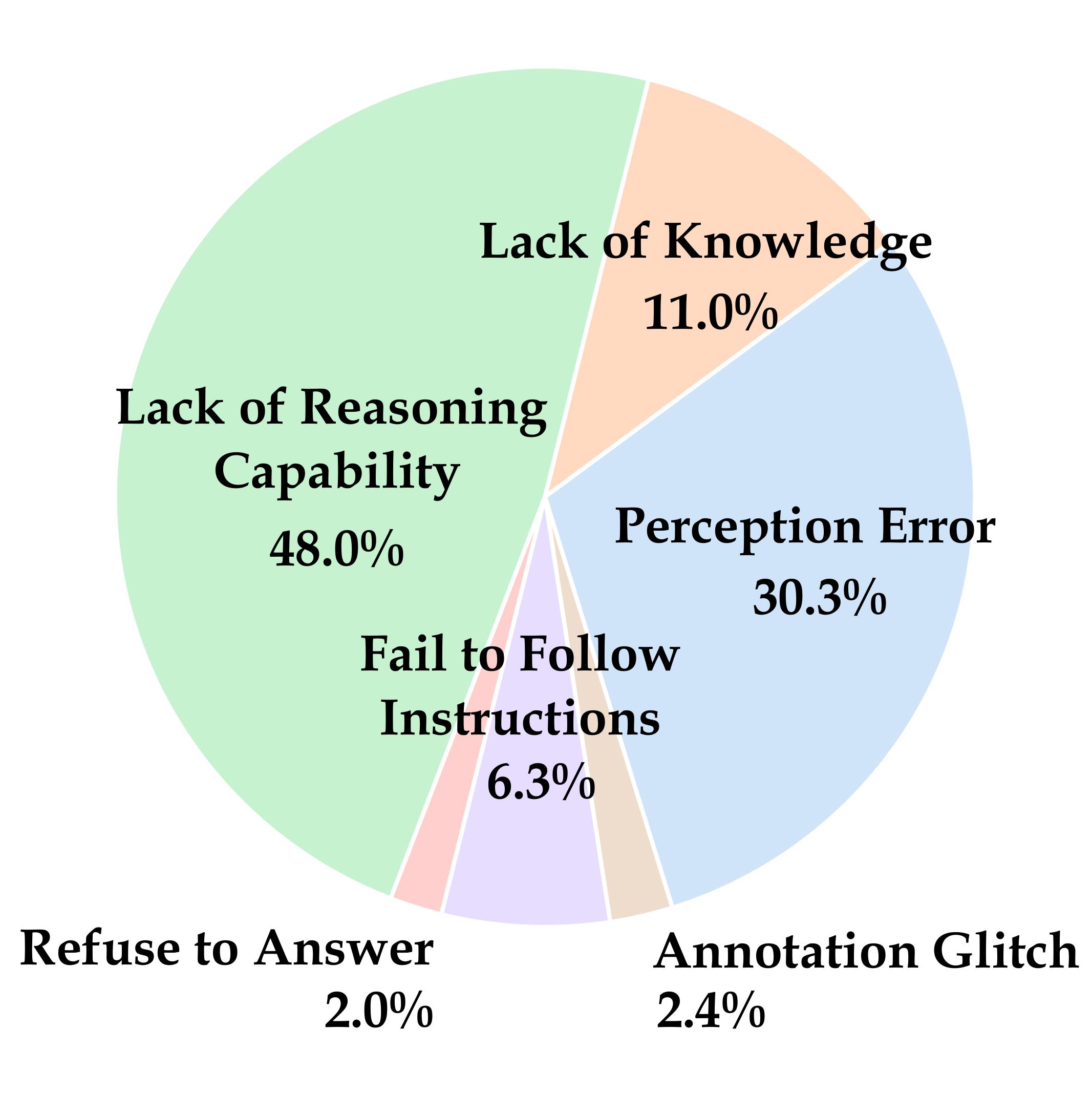
The task-wise error distribution of GPT-4o (0513) over a subset of 255 MEGA-Bench tasks
We provide some examples to inspect the behavior of different models on MEGA-bench. The results include both correct and error cases.




















@inproceedings{chen2025mega-bench,
title={MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks},
author={Chen, Jiacheng and Liang, Tianhao and Siu, Sherman and Wang, Zhengqing and Wang, Kai and Wang, Yubo and Ni, Yuansheng and Zhu, Wang and Jiang, Ziyan and Lyu, Bohan and Jiang, Dongfu and He, Xuan and Liu, Yuan and Hu, Hexiang and Yue, Xiang and Chen, Wenhu},
journal={International Conference on Learning Representations (ICLR)},
year={2025}
}